Trzy słowa powyżej mogą brzmieć jak bełkot SEO, ale są to słowa warte poznania, ponieważ zrozumienie jak ich używać oznacza, że możesz rozkazywać Googlebotowi. Co jest zabawne.
Zacznijmy więc od podstaw: istnieją trzy sposoby kontrolowania, które części twojej witryny będą indeksowane przez wyszukiwarki:
- Noindex: mówi wyszukiwarkom, aby nie uwzględniały twojej strony (stron) w wynikach wyszukiwania.
- Disallow: mówi im, aby nie indeksowały twojej strony (stron).
- Nofollow: mówi im, aby nie podążali za linkami na twojej stronie.
Co to jest znacznik meta Noindex?
Znacznik 'noindex' mówi wyszukiwarkom, aby nie uwzględniały strony w wynikach wyszukiwania.
Najczęstszą metodą noindexowania strony jest dodanie znacznika w sekcji head HTML, lub w nagłówkach odpowiedzi. Aby umożliwić wyszukiwarkom zobaczenie tej informacji, strona nie może być zablokowana (disallowed) w pliku robots.txt. Jeśli strona jest zablokowana poprzez plik robots.txt, Google nigdy nie zobaczy tagu noindex, a strona może nadal pojawiać się w wynikach wyszukiwania.
Aby powiedzieć wyszukiwarkom, aby nie indeksowały twojej strony, po prostu dodaj następujące elementy do sekcji </head>:
<meta name=”robots” content=”noindex, follow”>
Druga część znacznika content wskazuje tutaj, że wszystkie linki na tej stronie powinny być śledzone, co omówimy poniżej.
Alternatywnie, znacznik noindex może być użyty w X-Robots-Tag w nagłówku HTTP:
X-Robots-Tag: noindex
Po więcej informacji zobacz post Google Developers na temat specyfikacji meta tagu Robots i X-Robots-Tag w nagłówku HTTP.
Jak mogę użyć Noindex w pliku Robots.txt?
Znacznik 'noindex' w pliku robots.txt również mówi wyszukiwarkom, aby nie uwzględniały strony w wynikach wyszukiwania, ale jest to szybszy i łatwiejszy sposób na przeindeksowanie wielu stron naraz, szczególnie jeśli masz dostęp do pliku robots.txt. Na przykład, możesz noindexować wszystkie adresy URL w określonym folderze.
Oto przykład dyrektywy noindex, która może być umieszczona w pliku robots.txt:
Noindex: /robots-txt-noindexed-page/
Jednakże Google odradza stosowanie tej metody: John Mueller stwierdził, że „nie powinieneś na niej polegać”.
Co to jest dyrektywa Disallow?
Disallowing strony oznacza, że mówisz wyszukiwarkom, aby jej nie indeksowały, co musi być zrobione w pliku robots.txt Twojej witryny. Jest to przydatne, jeśli masz wiele stron lub plików, które nie są przydatne dla czytelników lub ruchu wyszukiwania, ponieważ oznacza to, że wyszukiwarki nie będą tracić czasu na indeksowanie tych stron.

Aby dodać disallow, po prostu dodaj następujące elementy do swojego pliku robots.txt:
Disallow: /your-page-url/
Jeśli strona ma linki zewnętrzne lub znaczniki kanoniczne wskazujące na nią, nadal może być indeksowana i pozycjonowana, dlatego ważne jest, aby połączyć disallow z tagiem noindex, jak opisano poniżej.
Słowo ostrzeżenia: poprzez wyłączenie strony skutecznie usuwasz ją z witryny.
Disallowed pages cannot pass PageRank to anywhere else – so any links on those pages are effectively useless from an SEO perspective – and disallowing pages that are supposed to be included can have disastrous results for your traffic, so be extra careful when writing disallow directives.
How Can I Combine Noindex and Disallow?
Noindex (page) + Disallow: Disallow nie może być połączone z noindex na stronie, ponieważ strona jest zablokowana i dlatego wyszukiwarki nie będą jej indeksować, aby wiedzieć, że nie mają pozostawić strony poza indeksem.
Noindex (robots.txt) + Disallow: Zapobiega to pojawianiu się stron w indeksie, a także uniemożliwia crawlowanie stron. Pamiętaj jednak, że żaden PageRank nie może przejść przez tę stronę.
Aby połączyć disallow z noindex w swoim pliku robots.txt, po prostu dodaj obie dyrektywy do swojego pliku robots.txt:
Disallow: /example-page-1/
Disallow: /example-page-2/
Noindex: /example-page-1/
Noindex: /example-page-2/
Co to jest tag nofollow?
Znacznik nofollow na linku mówi wyszukiwarkom, aby nie używały linku do decydowania o ważności połączonych stron (PageRank) lub odkrywania kolejnych adresów URL w obrębie tej samej witryny.
Powszechne zastosowania nofollow obejmują linki w komentarzach i innych treściach, których nie kontrolujesz, płatne linki, embedy takie jak widżety lub infografiki, linki w postach gościnnych lub cokolwiek off-topic, do czego nadal chcesz linkować ludzi.
Historycznie SEO również selektywnie nofollowowało linki, aby skierować wewnętrzny PageRank do ważniejszych stron.
Znaczniki Nofollow mogą być dodane w jednym z dwóch miejsc:
- Znaki <head> strony (aby nofollow wszystkie linki na tej stronie): <meta name=”robots” content=”nofollow” />
- Kod linku (aby nofollow pojedynczy link): <a href=”example.html” rel=”nofollow”>przykładowa strona</a>
A nofollow nie zapobiegnie całkowitemu indeksowaniu strony, do której prowadzi link; po prostu zapobiegnie indeksowaniu przez ten konkretny link. Nasze własne testy i innych wykazały, że Google nie będzie indeksować adresu URL, który znajdzie w linku nofollowed.
Google twierdzi, że jeśli inna witryna łączy się z tą samą stroną bez użycia tagu nofollow lub strona pojawia się w Sitemap, strona może nadal pojawiać się w wynikach wyszukiwania. Podobnie, jeśli jest to adres URL, o którym wyszukiwarki już wiedzą, dodanie linku nofollow nie spowoduje usunięcia go z indeksu.
We wrześniu 2019 roku Google ogłosiło aktualizację swojej dyrektywy nofollow i wprowadziło dwa nowe atrybuty linków, są to:
- rel=”sponsorowany” – Atrybut sponsorowany powinien być używany do identyfikacji linków, które służą celom reklamowym, w których obowiązują umowy sponsoringowe i kompensacyjne.
- rel=”ugc” – Jako atrybut User Generated Content, ta wartość jest zalecana dla linków w witrynach z treścią generowaną przez użytkownika, na przykład posty na forum i komentarze na blogu.
Dodatkowo, wszystkie linki oznaczone nofollow, sponsorowane lub ugc są teraz traktowane jako podpowiedzi dotyczące tego, które linki należy wziąć pod uwagę w wyszukiwaniu i podczas indeksowania, w przeciwieństwie do zwykłego sygnału, jak to było wcześniej w przypadku nofollow. Możesz dowiedzieć się więcej o tej aktualizacji w naszym poście, który obejmuje również wpływ tych aktualizacji wraz z spostrzeżeniami ekspertów.
Co to jest Noindex Nofollow?
Jak wspomniano powyżej, dodanie tagu nofollow do strony nie zapobiegnie jej całkowitemu indeksowaniu. Dlatego, aby zapobiec indeksowaniu strony, musisz ją również przeindeksować. Pozwoli to Google nadal być w stanie indeksować stronę, ale nie pojawi się ona w indeksie. Strony, które prawdopodobnie będziesz chciał zindeksować to: strony administratora/logina, wewnętrzne wyniki wyszukiwania i strony rejestracyjne. Aby całkowicie powstrzymać Google przed indeksowaniem strony, powinieneś również uniemożliwić jej indeksowanie (patrz wyżej).
Inne dyrektywy: Znaczniki kanoniczne, Paginacja i Hreflang
Istnieją inne sposoby, aby powiedzieć Google i innym wyszukiwarkom, jak traktować adresy URL:
- Znaczniki kanoniczne mówią wyszukiwarkom, która strona z grupy podobnych stron powinna być indeksowana. Strony kanoniczne (tj. strony drugorzędne, które kierują wyszukiwarki w stronę wersji podstawowej) nie są uwzględniane w indeksie. Jeśli masz oddzielne strony mobilne i stacjonarne, powinieneś kanonizować adresy URL mobilne do stacjonarnych.
- Paginacja grupuje wiele stron razem, tak aby wyszukiwarki wiedziały, że są one częścią zestawu. Wyszukiwarki powinny traktować priorytetowo stronę pierwszą z każdego zestawu podczas ustalania rankingu stron, ale wszystkie strony w ramach zestawu pozostaną w indeksie.
- Hreflang mówi wyszukiwarkom, które międzynarodowe wersje tej samej treści są dla jakiego regionu, tak aby mogły one nadać priorytet właściwej wersji dla każdego odbiorcy. Wszystkie te wersje pozostaną w indeksie.
Jak dużo czasu powinieneś poświęcić na zmniejszenie budżetu na indeksowanie?
Na forach SEO można usłyszeć wiele rozmów o tym, jak ważna dla SEO jest wydajność indeksowania i budżet indeksowania, i chociaż powszechną praktyką jest wyłączanie i noindeksowanie dużych grup stron, które nie przynoszą korzyści wyszukiwarkom ani czytelnikom (na przykład kod back-end, który jest używany tylko do prowadzenia witryny, lub niektóre rodzaje zduplikowanej treści), decydowanie o tym, czy ukryć wiele pojedynczych stron, prawdopodobnie nie jest najlepszym wykorzystaniem czasu i wysiłku.
Google lubi indeksować tak wiele adresów URL, jak to tylko możliwe, więc o ile nie ma konkretnego powodu, aby ukryć stronę przed wyszukiwarkami, zazwyczaj dobrze jest pozostawić tę decyzję Google. W każdym razie, nawet jeśli ukryć strony z wyszukiwarek, Google nadal będzie sprawdzać, czy te adresy URL uległy zmianie. Jest to szczególnie istotne, jeśli istnieją linki wskazujące na tę stronę; nawet jeśli Google zapomniało o adresie URL, może go ponownie odkryć, gdy następnym razem link do niego zostanie znaleziony.
Testowanie za pomocą Search Console, DeepCrawl i Robotto
Testowanie robots.txt za pomocą Search Console
Narzędzie robots.txt Tester w Search Console (pod Crawl) jest popularnym i w dużej mierze skutecznym sposobem na sprawdzenie nowej wersji pliku pod kątem błędów, zanim zostanie ona uruchomiona, lub przetestowanie konkretnego adresu URL, aby sprawdzić, czy jest on zablokowany:
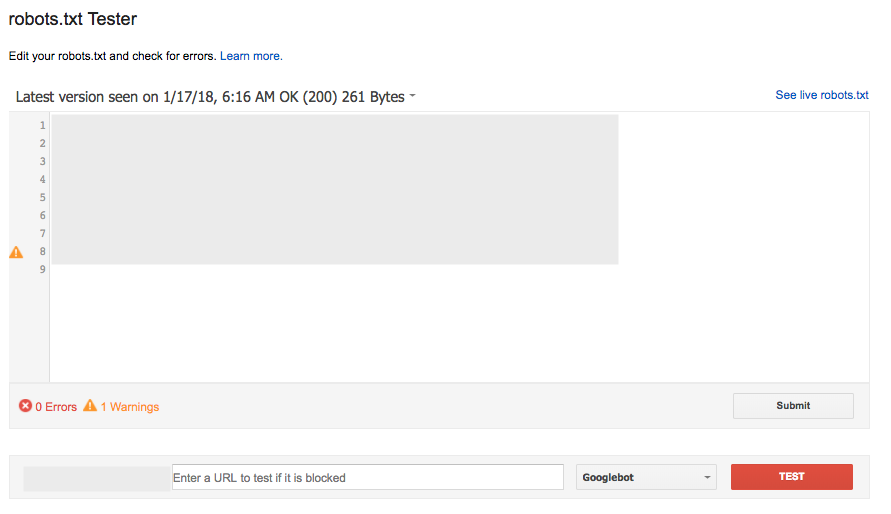
Jednakże narzędzie to nie działa dokładnie tak samo jak Google, z pewnymi subtelnymi różnicami w sprzecznych regułach Allow/Disallow, które są tej samej długości.
Narzędzie do testowania robots.txt raportuje je jako Dozwolone, jednak Google powiedziało: „Jeśli wynik jest nieokreślony, osoby oceniające robots.txt mogą zdecydować się albo na zezwolenie, albo na uniemożliwienie indeksowania. Z tego powodu nie zaleca się polegać na tym, że któryś z tych wyników będzie stosowany w całej sieci.'
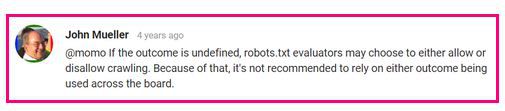
Po więcej szczegółów przeczytaj dyskusję na Webmaster Central Help Forum.
Znajdź wszystkie nieindeksowalne strony za pomocą DeepCrawl
Uruchom uniwersalne indeksowanie bez żadnych ograniczeń (ale z zastosowanymi warunkami robots.txt), aby umożliwić DeepCrawl zwrócenie wszystkich adresów URL i pokazanie wszystkich indeksowalnych/nieindeksowalnych stron.
Jeśli parametry URL zostały zablokowane przed Googlebotem za pomocą Search Console, możesz naśladować tę konfigurację dla swojego indeksowania za pomocą pola Usuń parametry w Ustawieniach zaawansowanych > Przepisywanie adresów URL.
Możesz następnie użyć poniższych raportów, aby sprawdzić, czy strona jest ustawiona tak, jak byś tego oczekiwał podczas pierwszego przeszukiwania, a następnie połączyć je z wbudowanymi dziennikami zmian podczas kolejnych przeszukiwań.
Indeksacja > Strony bezindeksowe
Ten raport pokaże Ci wszystkie strony, które zawierają znacznik bezindeksowy w meta informacjach, nagłówku HTTP lub pliku robots.txt.
Indeksacja > Disallowed Pages
Ten raport zawiera wszystkie adresy URL, które nie mogą być indeksowane z powodu reguły disallow w pliku robots.txt. Liczby dla obu tych raportów znajdują się w pulpicie nawigacyjnym Twojego raportu:
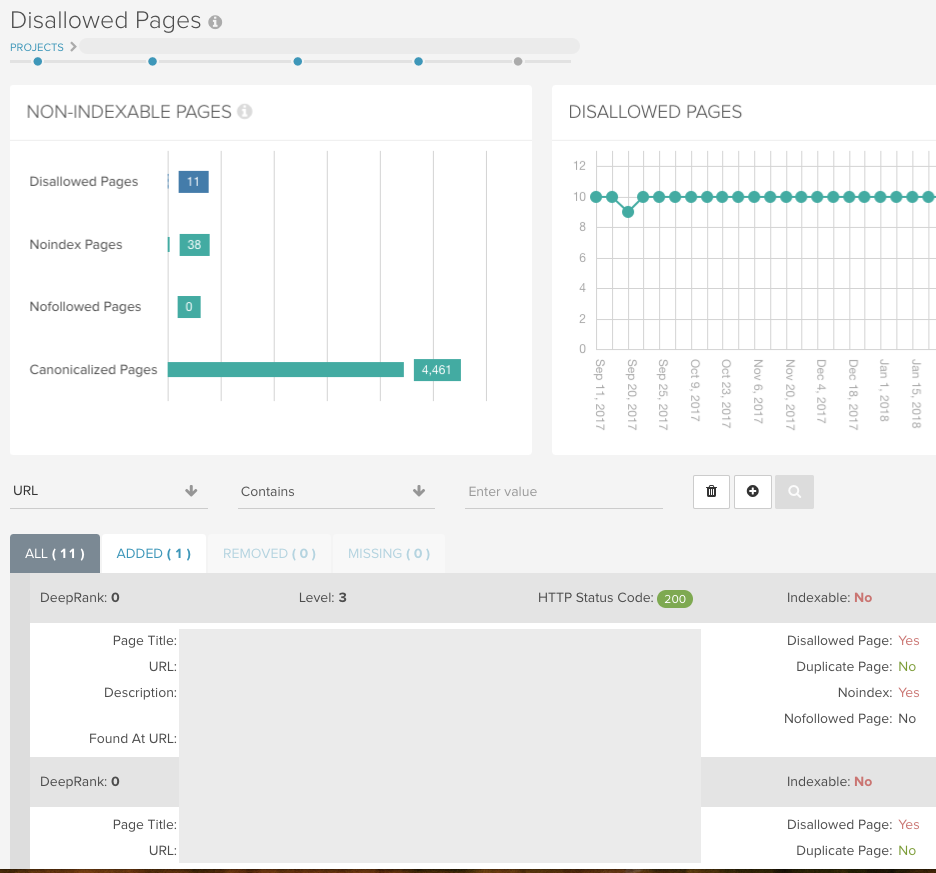
Użyj intuicyjnego raportowania w każdym z naszych raportów, aby sprawdzić poszczególne foldery i dostrzec wzorce w adresach URL, które w przeciwnym razie mógłbyś przeoczyć:

Testuj nowy plik robots.txt za pomocą DeepCrawl
Użyj funkcji DeepCrawl’s Robots.txt Overwrite w Ustawieniach zaawansowanych, aby zastąpić plik na żywo niestandardowym plikiem.

Następnym razem, gdy rozpoczniesz indeksowanie, możesz użyć wersji testowej zamiast wersji na żywo.
Raporty Added i Removed Disallowed URLs pokażą dokładnie, które adresy URL zostały dotknięte przez zmienione robots.txt, dzięki czemu ocena jest bardzo prosta.
Aby uzyskać więcej informacji, przeczytaj nasz przewodnik dotyczący zarządzania zmianami robots.txt za pomocą DeepCrawl.
Want More Like This?
Mamy nadzieję, że ten post okazał się przydatny w nauce o noindex, nofollow i disallow w celu kontroli indeksowania Twojej witryny.
Możesz przeczytać więcej na te tematy w naszej Bibliotece Technicznego SEO lub jeśli chcesz dowiedzieć się, jak przeprowadzić techniczny audyt SEO, przeczytaj nasz przewodnik.
Dodatkowo, jeśli chcesz być na bieżąco z najnowszymi aktualizacjami Google i zaleceniami dotyczącymi najlepszych praktyk, dlaczego nie zapisać się na nasze e-maile?
Zapętl mnie!
Autor

Sam Marsden
Sam Marsden jest menedżerem ds. SEO w DeepCrawl & Content Manager. Sam regularnie przemawia na konferencjach marketingowych, takich jak SMX i BrightonSEO, i jest współpracownikiem publikacji branżowych, takich jak Search Engine Journal i State of Digital.