Dit artikel is beoordeeld door de peer reviewers van The Journal of Electronic Publishing.
Alle inheemse Amerikaanse talen die tegenwoordig gesproken worden, worden geschreven in een Latijns alfabet, aangevuld met “accentletters”, of in een syllabarium, een set van ondeelbare syllabische symbolen, die elk een lettergreep voorstellen. De Apache en de Navaho talen behoren tot de inheemse Amerikaanse talen die een Latijns alfabet gebruiken, terwijl Cherokee, Inuiktitut, en Cree behoren tot de talen die moderne syllabarieën gebruiken. Syllabarieën, veelvoorkomend in oude schriften, werden gebruikt door de Maya’s en de Epi-Olmec mensen van Meso-Amerika.
Omdat een syllabarium minder expressief is dan een alfabetisch schrift, kan het worden getranscribeerd in een alfabetisch schrift zonder betekenis te verliezen. Leerlingen van de Cherokee taal leren een Latijnse transcriptie van het syllabarium om het gemakkelijker te maken Cherokee te leren. Dezelfde eigenschappen die het mogelijk maken Cherokee te transcriberen in het Latijnse alfabet maken het mogelijk zetgereedschappen te creëren voor syllabarieën. Een modern zetgereedschap dat ontworpen is om met syllabarieën om te gaan zou gebruikers in staat moeten stellen om de symbolen ofwel direct in te typen (bijvoorbeeld met een Unicode editor als het script ondersteund wordt door de Unicode Standaard, of met een editor die een speciale karakterset ondersteunt), of door gebruik te maken van een standaard Latijnse transcriptie. (Unicode geeft een uniek, door de computer leesbaar nummer – een codepunt genoemd – voor elk teken; dit nummer werkt op verschillende platforms, programma’s en talen.)
Dit artikel gaat over Omega, een modern typesettingsysteem gebaseerd op TeX, dat standaard Unicode tekstbestanden accepteert, maar in staat is om elke denkbare invoercodering te verwerken. Bovendien introduceert het een aantal mogelijkheden die het leven van de ontwerpers van programma’s heel gemakkelijk maken. Ik heb deze functies gebruikt om een aantal programma’s te ontwikkelen die de voorbereiding van documenten in de Cherokee en Inuktitut taal vergemakkelijken.
TeX en LaTeX
TeX is een legendarisch computerprogramma dat is ontworpen door Donald E. Knuth, de beroemde professor in de computerwetenschappen aan de Stanford Universiteit. Het is een digitale zetmachine, een computerprogramma dat het werk van een typograaf doet, door het uiterlijk van de gedrukte pagina te beschrijven (Knuth, 1993). TeX verwerkt een invoerbestand dat zowel tekst- als zetopdrachten bevat. Leslie Lamport ontwierp de LaTeX markup Language (Lamport, 1994) die bovenop de TeX zet-engine zit om het maken van invoerbestanden te vergemakkelijken. Omdat veel mensen bekend zijn met LaTeX maar niet weten wat de relatie is met TeX, denken zij ten onrechte dat LaTeX en TeX twee verschillende programma’s zijn. TeX produceert echter een apparaat onafhankelijk (DVI) bestand dat de tekst en grafische elementen op een pagina beschrijft en dat verder kan worden verwerkt om andere talen voor paginabeschrijving te genereren, zoals PostScript uitvoer. Knuth ontwierp ook METAFONT, dat een andere taal voor het beschrijven en genereren van lettertypen implementeert (Knuth, 1992).
Hoewel de ontwikkeling van TeX is bevroren sinds Knuth heeft besloten TeX en METAFONT niet verder te ontwikkelen, ontstaan er nog steeds nieuwe zetmachines die de mogelijkheden van TeX uitbreiden. De meest opmerkelijke TeX uitbreidingen zijn: pdfTeX (Thanh et al., 1999), dat direct PDF bestanden kan produceren; e-TeX (NTS Team en Beiettenlohner, 1998), dat een TeX uitbreiding is die de capaciteit en mogelijkheden van TeX vergroot door bidirectioneel zetwerk mogelijk te maken; en Omega dat de Unicode uitbreiding van TeX is die in staat is om Unicode invoer te nemen en het in vele schrijfrichtingen te zetten (Syropoulos et al., 2002). Bovendien kan Omega XML- en MathML-inhoud produceren. Merk op dat MathML een XML-toepassing is die primair is bedoeld om het gebruik en hergebruik van wiskundige en wetenschappelijke inhoud op het Web te vergemakkelijken. Met behulp van Omega kan een letterzetter pre-processors schrijven die een brug slaan tussen Unicode en letterzetten. (Merk op dat Lambda een bijnaam is voor LaTeX wanneer het wordt gebruikt met Omega.)
Cherokee
Cherokee is een Iroquiaanse taal die door zo’n 20.000 mensen wordt gesproken, meestal als tweede taal. Er zijn slechts twee dialecten overgebleven: Oklahoma (gesproken door ongeveer 17.000 mensen) en North Carolina (gesproken door de overige 3.000 mensen).
Het Cherokee schrift werd in de 19e eeuw ontwikkeld door een Cherokee genaamd 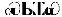 Sequoya (die de naam George Guess of George Giss gebruikte in de omgang met blanken). Sommigen denken dat Sequoya de enige persoon was die ooit alleen een schrift heeft ontwikkeld, maar er zijn anderen die dat hebben gedaan. Bijvoorbeeld: de Griek St. Clement van Ohrid ontwikkelde het Cyrillisch schrift (Kirilitsa), in een vorm die dicht aanleunt bij die welke vandaag nog in gebruik is, gebaseerd op het vroegere werk van de Griekse monniken St. Cyril; St. Methodius ontwikkelde een Slavisch schrift genaamd Glagolitsa; Eerwaarde James Evans creëerde het schrijfsysteem van de Inuktitut taal gebaseerd op vroeger werk aan de Cree taal, dat op zijn beurt gebaseerd was op werk aan de Ojibway taal; en Afaka Atumisi vond het Ndjuka syllabary uit.
Sequoya (die de naam George Guess of George Giss gebruikte in de omgang met blanken). Sommigen denken dat Sequoya de enige persoon was die ooit alleen een schrift heeft ontwikkeld, maar er zijn anderen die dat hebben gedaan. Bijvoorbeeld: de Griek St. Clement van Ohrid ontwikkelde het Cyrillisch schrift (Kirilitsa), in een vorm die dicht aanleunt bij die welke vandaag nog in gebruik is, gebaseerd op het vroegere werk van de Griekse monniken St. Cyril; St. Methodius ontwikkelde een Slavisch schrift genaamd Glagolitsa; Eerwaarde James Evans creëerde het schrijfsysteem van de Inuktitut taal gebaseerd op vroeger werk aan de Cree taal, dat op zijn beurt gebaseerd was op werk aan de Ojibway taal; en Afaka Atumisi vond het Ndjuka syllabary uit.
 Cherokee syllabary
Cherokee syllabary Inuktitut
Inuktitut is de taal van de Inuit (ook bekend als “Eskimo’s,” maar de term wordt als beledigend beschouwd door de Inuit die in Canada en Groenland wonen). De taal wordt gesproken door ongeveer 152.000 mensen in Groenland, Canada, Alaska en de Tsjoekotka Autonome Okrug, die in het uiterste noordoosten van de Russische Federatie ligt. Het Inuktitut syllabisch wordt gebruikt door Inuit die in Canada leven, vooral in het nieuwe Canadese territorium Nunavut. Dit schrijfsysteem werd uitgevonden door dominee James Evans, een Wesleyan missionaris. De tabel hieronder toont de Inuktitut syllabics en de Latijnse transcriptie van de Inuktitut symbolen. (Merk op dat het Inuktitut schrift ondersteund wordt door Unicode en dat het eigenlijk deel uitmaakt van de Unified Canadian Aboriginal Syllabics sectie van de Unicode Standaard.)
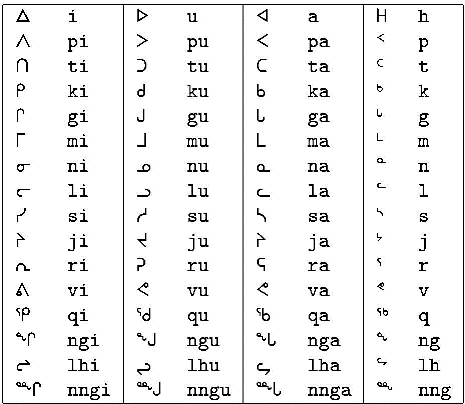 Inuktitut syllabary
Inuktitut syllabary Er zijn momenteel twee Inuktitut orthografieën (orthografie is de kunst of studie van de correcte spelling volgens gevestigd gebruik): de Anglicaanse (die vooral in Nunavut wordt gebruikt) en de Katholieke (die vooral in Quebec wordt gebruikt). Zij verschillen in de manier waarop zij “lange” klinkers schrijven – lettergrepen met twee identieke klinkers. De Anglicaanse orthografie plaatst een punt boven een korte lettergreep om deze lang te maken; de Katholieke orthografie gebruikt twee symbolen. Let op de verschillende weergaven van het woord “ataata” (vader) hieronder.
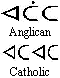 “ataata” (vader) in Inuktitut orthografieën
“ataata” (vader) in Inuktitut orthografieën Syllabarieën zetten met Lambda
De zetgereedschappen die ik heb ontworpen voor Cherokee en Inuktitut tekst kunnen worden gebruikt met het Omega zet-systeem, omdat ze sterk afhankelijk zijn van de Omega Translation Processes (OmegaTPs). Technisch gesproken is een OmegaTP een deterministische eindige-toestand automaat (een abstracte “machine” – een wiskundige functie – gebruikt in de studie van berekeningen en talen) die wordt gebruikt om een input karakterstroom te transformeren. Een OmegaTP kan bijvoorbeeld een ISO-Latin-1 tekeninvoerstroom omzetten in een UCS-2 tekenstroom. Hoewel we precies hetzelfde effect kunnen krijgen als we een of andere externe preprocessor en TeX gebruiken, zijn preprocessoren bijzonder moeilijk te gebruiken. Dus hebben we een systeem gebouwd dat geen preprocessor nodig heeft.
Eerst moesten we de geldige codering voor de Cherokee of Inuktiut tekst bepalen. We stelden vast dat aangezien beide syllabaries worden ondersteund door de Unicode standaard, we Unicode invoerbestanden zouden toestaan (ofwel UCS-2 of UTF-8). Aangezien beide syllabarieën standaard Latijnse transcripties hebben, hebben we besloten ook die toe te staan. Tenslotte zijn er een aantal acht-bits karaktersets voor het Inuktitut, dus hebben we er een gekozen. Om met Unicode-invoer te kunnen werken, hebben we gebruik gemaakt van Unicode-gecodeerde virtuele lettertypen. Een virtueel lettertype is een mechanisme waarmee we een lettertype maken dat eigenlijk glyphs uit bestaande lettertypes tekent. Om een nieuw virtueel lettertype te maken, moeten we een bestand met virtuele eigenschappen samenstellen, waarin de virtuele glyphs van het lettertype worden beschreven, die worden getekend uit bestaande lettertypes, evenals hun afmetingen, kerningparen, en ligatuurparen. Bovendien worden virtuele fonts gebruikt om nieuwe glyphs te maken, zoals letters met accenten, onderstreepte glyphs, enzovoort.
Voor Cherokee gebruikt Omega een PostScript versie van het officiële Cherokee TrueType font, ontwikkeld door Tonia Williams van de Oklahoma Cherokee Nation, dat geen Latijnse glyphs bevat en niet het nummeringssysteem van Sequoya volgt. Voor het Inuktitut wordt gebruik gemaakt van een PostScript-versie van het Nunacom TrueType-lettertype, ontwikkeld door Nortext, een Canadees bedrijf dat in het begin van de jaren tachtig als pionier fungeerde op het gebied van lettertypes voor Aboriginal-talen. De virtuele lettertypen voor de Inuktitut taal putten glyphs uit het Nunacom lettertype, de standaard Computer Modern lettertypen die elke TeX installatie vergezellen, en een lettertype dat ik heb gefabriceerd, als aanvulling op de lettertypen in de standaard TeX distributie.
Voor het Cherokee schrift hoefden we slechts een OmegaTP te ontwerpen, omdat er voor zover wij weten geen 8-bit Cherokee codepagina bestaat. Het ontwerp van de OmegaTP was bijna recht-toe-recht-aan, op een eenvoudig probleem na: de behandeling van de lettergreep die optreedt wanneer een “s” niet wordt gevolgd door een “a,” “e,” “i,” “o,” “u,” of “v.” OmegaTP “duwt terug” het teken dat onmiddellijk volgt op het teken “s”. Anders genereren we eenvoudig het corresponderende symbool. Bijvoorbeeld, als het hoofd van de invoerstroom “se” is, dan zal OmegaTP het teken 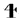 teruggeven, enzovoort. Bijvoorbeeld, de invoer “elohinodohiyigesesti” (vrede op aarde) zal worden getypt als
teruggeven, enzovoort. Bijvoorbeeld, de invoer “elohinodohiyigesesti” (vrede op aarde) zal worden getypt als
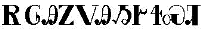
Typen van Inuktitut met Lambda is complexer dan typen van Cherokee omdat we feitelijk één Latijnse transcriptie hebben die verschillende uitvoer kan produceren, afhankelijk van de orthografie die wordt verondersteld, en een geldige acht-bits codepagina. Daarom moesten we drie OmegaTP’s coderen om alle mogelijke gevallen te behandelen. Bovendien moesten wij gebruikers de mogelijkheid bieden om de invoermethode op een transparante manier te kiezen. Dus bieden wij de opties: “nunavut,” “quebec,” en “inscii.” We hadden veel van dezelfde problemen met het Inuktitut als met het Cherokee, zoals tekens die zowel op zichzelf kunnen staan als een lettergreep kunnen beginnen. De tabel hieronder toont de indeling van de ISCII tekenset die overeenkomt met de OmegaTP implementaties.
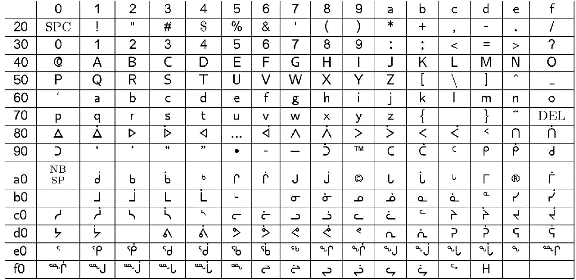 ISCII tekenset
ISCII tekenset Omdat Omega woordafbreking kan uitvoeren indien dat wordt opgedragen, hebben wij de afbrekingsregels van het Inuktitut gecodeerd zodat de gereedschappen compleet zijn.
Omega en de andere Indiaanse talen
Naast de Cherokee en de Inuktitut talen, gebruiken de Blackfoot, de Dene (Carrier), de Cree en de Naskapi talen een niet-Latijns schrift. Hun schriften zijn opgenomen in het PDF-bestand Unified Canadian Aboriginal Syllabics sectie van de Unicode Standaard. Op basis van onze eerdere ervaring is het dus een tamelijk eenvoudige taak om soortgelijke hulpmiddelen te maken. We denken echter dat het een veel beter idee is om een set gereedschappen te maken die gebruikt kan worden om elke Amerikaanse taal die niet het Latijnse schrift gebruikt te zetten. Dit lijkt misschien nogal beperkend, maar de gereedschappen die vandaag de dag beschikbaar zijn, voldoen prima voor de Amerikaanse talen die het Latijnse schrift gebruiken.
Natuurlijk zijn er enkele talen die het Latijnse schrift gebruiken, zoals Smalgyax en Tlingit, die enkele speciale letters hebben (b.v. onderstreepte letters), en de Apache taal, die enkele letters heeft die ook in sommige Europese talen voorkomen, maar tekst in deze talen kan worden verwerkt met gereedschappen die al wijd en zijd beschikbaar zijn. Bijvoorbeeld, de Tlingit zin 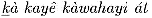 (rechten), de Smalgyax zin
(rechten), de Smalgyax zin 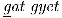 (rechten), en het Apache woord
(rechten), en het Apache woord  (vis) en
(vis) en 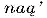 (maïs), zijn gezet met deze standaard methodes. Natuurlijk is het mogelijk om speciale virtuele lettertypen te maken die al deze speciale Latijnse letters bevatten (Syropoulous et al., 2002).
(maïs), zijn gezet met deze standaard methodes. Natuurlijk is het mogelijk om speciale virtuele lettertypen te maken die al deze speciale Latijnse letters bevatten (Syropoulous et al., 2002).
De situatie is heel anders als het gaat om het letterzetten van oude Amerikaanse schriften zoals het Epi-Olmec en het Maya-schrift. Allereerst zijn de symbolen van deze schriften niet gedefinieerd in de Unicode-standaard. Bovendien is de schrijfrichting niet westers (d.w.z. van links naar rechts en van boven naar beneden), maar identiek aan de schrijfrichting van het klassieke Mongoolse Oejgoerschrift (d.w.z. van boven naar beneden en van links naar rechts). Wij werken aan een instrument waarmee onderzoekers de weinige beschikbare Epi-Olmec-teksten kunnen zetten. Een Epi-Olmec-lettertype is bijna klaar. Het lettertype zelf is gebaseerd op de beschrijving van het schrift zoals beschreven in Epi-Olmec Hieroglyphic Writing. Aangezien het schrift ruwweg een syllabarium is, hebben we een eenvoudige OmegaTP gemaakt die een subset van het syllabarium kan verwerken, maar we hebben ontdekt dat de commando’s die kunnen worden gebruikt om de schrijfrichting in te stellen niet goed functioneren met ons lettertype. Dus moesten wij de OmegaTP verbeteren om daadwerkelijk een zet-opdracht te produceren en niet slechts een vertaling. Om het verschil te zien, kunt u de volgende voorbeelden bekijken:
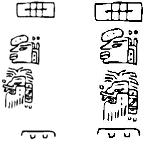
De symbolen links zijn gezet door alleen te vertrouwen op Omega’s mogelijkheden; die rechts zijn gezet door een verbeterde OmegaTP te gebruiken. Natuurlijk is er nog veel werk te doen en daarom denken we niet dat de hulpmiddelen binnenkort beschikbaar zullen zijn.
Conclusies en toekomstig werk
We hebben de hulpmiddelen gepresenteerd die we hebben ontwikkeld voor het zetten van Cherokee en Inuktitut teksten. De programma’s zijn vrij verkrijgbaar bij het Comprehensive TeX Archive Network (CTAN) op ftp://ftp.dante.de of ftp://ftp.tex.ac.uk of rechtstreeks bij mij. Er is nog veel werk te doen aan deze hulpmiddelen – vooral aan het Cherokee hulpmiddel – maar zij kunnen worden gebruikt als model om nieuwe hulpmiddelen te maken voor andere zetbehoeften. Aangezien de komende versies van Omega in staat zullen zijn om Unicode surrogaten te begrijpen, zal het zelfs mogelijk zijn om de hier gepresenteerde ideeën toe te passen op het probleem van het zetten van Byzantijnse en Westerse muziekteksten.

Apostolos Syropoulos, voorzitter en stichtend lid van de Greek TeX Friends Group, heeft verschillende LaTeX pakketten geschreven om het zetten van Griekse taal met LaTeX te vergemakkelijken. Hij is de auteur van het eerste boek over LaTeX in het Grieks, LATEX. Hij is co-auteur van TEX and Electronic Typesetting: 110 Questions and Answers, de Griekse FAQ voor TeX, LaTeX, METAFONT en lettertypes in het algemeen. Hij heeft een B.Sc. in natuurkunde, een M.Sc. in computerwetenschappen en een Ph.D. in theoretische computerwetenschappen. Hij werkt momenteel aan boeken over LaTeX en Digitale Typografie en over programmeren met Perl. Hij heeft vele artikelen geschreven over informatica in het algemeen en typografie in het bijzonder. Zijn wetenschappelijke interesses omvatten programmeertaaltheorie, concurrency, logica (vooral lineaire en fuzzy logic), en elektronisch zetwerk met TEX. Hij kan programmeren in Pascal, FORTRAN, Perl, Modula-2, C/C++, LML, SML, Prolog, en Java, en hij spreekt Grieks, Engels, een beetje Zweeds, en een beetje Russisch. Zijn website is te vinden op http://obelix.ee.duth.gr/~apostolo/. Hij kan per e-mail worden bereikt op [email protected].
Knuth, D.E. (1992). Het metafontboek. Deel C van Computers and Typesetting. Reading, MA: Addison-Wesley.
Knuth, D.E. (1993). Het TeX Boek. Deel A van Computers and Typesetting. Reading, MA: Addison-Wesley.
Lamport, L. (1994). LaTeX: A Document Preparation System, 2nd ed. Addison-Wesley.
NTS Team en Beiettenlohner, P. (1998). De e-TeX handleiding, Versie 2. MAPS, 20, 1998, 248-263.
Syropoulos, A., Tsolomitis, A., and Sofroniou, N. (2002). Digitale typografie met behulp van LaTeX. New York: Springer-Verlag.
Thanh, H.T., Rahtz, S., and Hagen, H. (1999). De pdfTeX gebruikershandleiding. MAPS, 22, 1999, 94-114.
Links uit dit artikel
Comprehensive TeX Archive Network (CTAN), http://www.ctan.org
Donald E. Knuth, http://www-cs-faculty.stanford.edu/~knuth
Epi-Olmec Hieroglyphic Writing, http://www.albany.edu/anthro/maldp/papers.htm
Nortext, http://www.nortext.com
Oklahoma Cherokee Nation, http://www.cherokee.org
Unicode Standard, http://www.unicode.org
SectieUnified Canadian Aboriginal Syllabics van de Unicode Standard, http://www.unicode.org/charts/PDF/U1400.pdf