De drie bovenstaande woorden klinken misschien als SEO-brabbeltaal, maar het zijn wel woorden die het waard zijn om te kennen, want als je weet hoe je ze moet gebruiken, kun je Googlebot op zijn nummer zetten.
Dus laten we beginnen met de basis: er zijn drie manieren om te bepalen welke delen van je site zoekmachines zullen crawlen:
- Noindex: vertelt zoekmachines om je pagina(‘s) niet op te nemen in zoekresultaten.
- Disallow: vertelt ze om je pagina(‘s) niet te crawlen.
- Nofollow: geeft aan dat de links op uw pagina niet gevolgd mogen worden.
Wat is een Noindex Meta Tag?
Een ‘noindex’ tag vertelt zoekmachines om de pagina niet op te nemen in de zoekresultaten.
De meest gebruikte methode om een pagina te noindexeren is door een tag toe te voegen in de head sectie van de HTML, of in de response headers. Om zoekmachines in staat te stellen deze informatie te zien, mag de pagina nog niet zijn geblokkeerd (afgekeurd) in een robots.txt-bestand. Als de pagina is geblokkeerd via uw robots.txt-bestand, zal Google de noindex-tag nooit zien en kan de pagina nog steeds in de zoekresultaten verschijnen.
Om zoekmachines te vertellen dat ze uw pagina niet mogen indexeren, voegt u het volgende toe aan de </head>-sectie:
<meta name=”robots” content=”noindex, follow”>
Het tweede deel van de content tag hier geeft aan dat alle links op deze pagina gevolgd moeten worden, wat we hieronder zullen bespreken.
Aternatief kan de noindex-tag worden gebruikt in een X-Robots-Tag in de HTTP-header:
X-Robots-Tag: noindex
Voor meer informatie zie Google Developers’ post over Robots meta tag en X-Robots-Tag HTTP header specificaties.
Hoe kan ik Noindex gebruiken in een Robots.txt bestand?
Een ‘noindex’ tag in je robots.txt bestand vertelt zoekmachines ook om de pagina niet op te nemen in de zoekresultaten, maar het is een snellere en makkelijkere manier om veel pagina’s in één keer te noindexeren, vooral als je toegang hebt tot je robots.txt bestand. U kunt bijvoorbeeld alle URL’s in een specifieke map noindexeren.
Hier volgt een voorbeeld van een noindex-richtlijn die in het robots.txt-bestand kan worden geplaatst:
Noindex: /robots-txt-noindexed-page/
Het gebruik van deze methode wordt echter afgeraden door Google: John Mueller heeft verklaard dat ‘je er niet op moet vertrouwen’.
Wat is een Disallow-richtlijn?
Het weigeren van een pagina betekent dat je zoekmachines vertelt dat ze de pagina niet mogen crawlen, wat moet gebeuren in het robots.txt-bestand van je site. Dit is handig als u veel pagina’s of bestanden hebt waar lezers of zoekverkeer niets aan hebben, omdat zoekmachines dan geen tijd verspillen aan het crawlen van die pagina’s.

Om een disallow toe te voegen, voegt u het volgende toe aan uw robots.txt-bestand:
Disallow: /uw-pagina-url/
Als de pagina externe links of canonieke tags heeft die ernaar verwijzen, kan deze nog steeds worden geïndexeerd en gerangschikt, dus het is belangrijk om een disallow te combineren met een noindex-tag, zoals hieronder beschreven.
Waarschuwing: als u een pagina disallowt, verwijdert u deze in feite van uw site.
Geweerde pagina’s kunnen geen PageRank aan andere pagina’s doorgeven – dus alle links op die pagina’s zijn vanuit SEO-perspectief nutteloos – en het weigeren van pagina’s die wel zouden moeten worden opgenomen, kan desastreuze gevolgen hebben voor je verkeer, dus wees extra voorzichtig bij het schrijven van disallow-richtlijnen.
Hoe kan ik Noindex en Disallow combineren?
Noindex (pagina) + Disallow: Disallow kan niet gecombineerd worden met noindex op de pagina, omdat de pagina geblokkeerd wordt en zoekmachines deze dus niet zullen crawlen om te weten dat ze de pagina niet uit de index mogen laten.
Noindex (robots.txt) + Disallow: Dit voorkomt dat pagina’s in de index verschijnen, en voorkomt ook dat de pagina’s worden gecrawld. Denk er echter aan dat er geen PageRank kan worden doorgegeven via deze pagina.
Om een disallow met een noindex in uw robots.txt te combineren, voegt u beide richtlijnen toe aan uw robots.txt-bestand:
Disallow: /voorbeeld-pagina-1/
Disallow: /voorbeeld-pagina-2/
Noindex: /voorbeeld-pagina-1/
Noindex: /voorbeeld-pagina-2/
Wat is een Nofollow-tag?
Een nofollow-tag op een link vertelt zoekmachines dat ze de link niet mogen gebruiken om het belang van de gelinkte pagina’s te bepalen (PageRank) of om meer URL’s binnen dezelfde site te ontdekken.
Gemeenschappelijk gebruik van nofollows zijn links in commentaren en andere inhoud die je niet beheert, betaalde links, embeds zoals widgets of infographics, links in gastberichten, of iets off-topic waar je mensen toch naar wilt linken.
Historisch gezien hebben SEO’s ook selectief links nofollow gemaakt, om interne PageRank naar belangrijkere pagina’s te trechteren.
Nofollow tags kunnen op een van de volgende twee plaatsen worden toegevoegd:
- De <head> van de pagina (om alle links op die pagina nofollow te maken): <meta name=”robots” content=”nofollow” />
- De linkcode (om een individuele link te nofollowen): <a href=”voorbeeld.html” rel=”nofollow”>voorbeeldpagina</a>
Een nofollow voorkomt niet dat de gelinkte pagina volledig wordt gecrawld; het voorkomt alleen dat deze wordt gecrawld via die specifieke link. Onze eigen tests en die van anderen hebben aangetoond dat Google een URL die in een nofollow-link voorkomt, niet zal crawlen.
Google stelt dat als een andere site naar dezelfde pagina linkt zonder een nofollow-tag te gebruiken of als de pagina in een Sitemap voorkomt, de pagina toch in de zoekresultaten kan verschijnen. Evenzo, als het een URL is die zoekmachines al kennen, zal het toevoegen van een nofollow-link deze niet uit de index verwijderen.
In september 2019 kondigde Google een update aan van hun nofollow-richtlijn en introduceerde twee nieuwe link-attributen, dit zijn:
- rel=”gesponsord” – Het gesponsorde attribuut moet worden gebruikt om links te identificeren die voor advertentiedoeleinden zijn, waar sponsor- en compensatieovereenkomsten van kracht zijn.
- rel=”ugc” – Als het attribuut voor door gebruikers gegenereerde inhoud, wordt deze waarde aanbevolen voor links binnen door gebruikers gegenereerde inhoudsites, bijvoorbeeld forumberichten en blogcommentaren.
Daarnaast worden alle links die zijn gemarkeerd met nofollow, gesponsord of ugc nu behandeld als hints met betrekking tot welke links rekening moet worden gehouden bij het zoeken en bij het crawlen, in plaats van slechts een signaal, zoals eerder voor nofollow werd gebruikt. U kunt meer over deze update te weten komen in onze post, waarin ook de impact hiervan wordt besproken, samen met inzichten van experts.
Wat is Noindex Nofollow?
Zoals hierboven vermeld, kan een pagina niet volledig worden gecrawld door er een nofollow-tag aan toe te voegen. Om te voorkomen dat de pagina geïndexeerd wordt, moet je de pagina ook noindexeren. Hierdoor kan Google de pagina nog wel crawlen, maar zal deze niet meer in de index voorkomen. Pagina’s die u waarschijnlijk wilt noindexeren zijn admin/login pagina’s, interne zoekresultaten en registratie pagina’s. Om te voorkomen dat Google de pagina volledig crawlt, moet u deze ook disallowen (zie boven).
Andere directives: Canonical Tags, Pagination en Hreflang
Er zijn nog andere manieren om Google en andere zoekmachines te vertellen hoe ze URL’s moeten behandelen:
- Canonical tags vertellen zoekmachines welke pagina van een groep vergelijkbare pagina’s geïndexeerd moet worden. Canonicalized (d.w.z. secundaire pagina’s die zoekmachines naar een primaire versie leiden) worden niet in de index opgenomen. Als je aparte mobiele en desktop sites hebt, wordt je verondersteld je mobiele URL’s te canonicaliseren naar je desktop URL’s.
- Paginering groepeert meerdere pagina’s samen zodat zoekmachines weten dat ze deel uitmaken van een set. Zoekmachines moeten prioriteit geven aan pagina één van elke set bij het rangschikken van pagina’s, maar alle pagina’s binnen de set blijven in de index.
- Hreflang vertelt zoekmachines welke internationale versies van dezelfde inhoud voor welke regio zijn, zodat ze prioriteit kunnen geven aan de juiste versie voor elk publiek. Al deze versies blijven in de index.
Hoeveel tijd moet je besteden aan het verkleinen van het crawlbudget?
Je hoort op SEO-forums misschien veel praten over hoe belangrijk crawl efficiency en crawl budget is voor SEO en, hoewel het gebruikelijk is om grote groepen pagina’s die geen voordeel hebben voor zoekmachines of lezers te weigeren en noindexeren (bijvoorbeeld back-end code die alleen wordt gebruikt voor het runnen van de site, of sommige soorten duplicate content), is de beslissing om veel individuele pagina’s te verbergen waarschijnlijk niet de beste besteding van tijd en moeite.
Google indexeert graag zo veel mogelijk URL’s, dus tenzij er een specifieke reden is om een pagina voor zoekmachines te verbergen, is het meestal prima om de beslissing aan Google over te laten. Hoe dan ook, zelfs als u pagina’s verbergt voor zoekmachines, zal Google blijven controleren of die URL’s zijn veranderd. Dit is vooral van belang als er links zijn die naar die pagina verwijzen; zelfs als Google de URL is vergeten, kan deze de volgende keer dat er een link naar wordt gevonden toch weer worden gevonden.
Testen met Search Console, DeepCrawl en Robotto
Robots.txt testen met Search Console
De tool robots.txt Tester tool in Search Console (onder Crawl) is een populaire en grotendeels effectieve manier om een nieuwe versie van je bestand te controleren op eventuele fouten voordat deze live gaat, of om een specifieke URL te testen om te zien of deze geblokkeerd is:
Deze tool werkt echter niet exact hetzelfde als Google, met enkele subtiele verschillen in conflicterende Allow/Disallow-regels die even lang zijn.
De robots.txt-testtool rapporteert deze als toegestaan, maar Google heeft gezegd: “Als de uitkomst niet is gedefinieerd, kunnen robots.txt-evaluators ervoor kiezen om crawlen toe te staan of niet toe te staan. Daarom wordt het niet aanbevolen om erop te vertrouwen dat een van beide resultaten over de hele linie wordt gebruikt.”
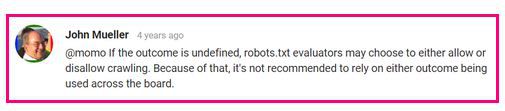
Voor meer details, lees deze Webmaster Central Help Forum-discussie.
Vind alle niet-dexeerbare pagina’s met DeepCrawl
Voer een universele crawl uit zonder beperkingen (maar met de robots.txt-voorwaarden) zodat DeepCrawl al uw URL’s kan retourneren en u alle indexeerbare/niet-indexeerbare pagina’s kan tonen.
Als u URL-parameters hebt die zijn geblokkeerd voor Googlebot met Search Console, kunt u deze opzet nabootsen voor uw crawl met behulp van het veld Parameters verwijderen onder Geavanceerde instellingen > URL herschrijven.
U kunt dan de volgende rapporten gebruiken om te controleren of de site is opgezet zoals u verwacht bij uw eerste crawl, en deze vervolgens combineren met de ingebouwde wijzigingslogs bij volgende crawls.
Indexatie > Noindex Pagina’s
Dit rapport toont u alle pagina’s die een noindex tag bevatten in de meta-informatie, HTTP header of robots.txt bestand.
Indexatie > Disallowed Pages
Dit rapport bevat alle URL’s die niet gecrawld kunnen worden vanwege een disallow regel in het robots.txt bestand. In het dashboard van uw rapport vindt u cijfers voor beide rapporten:
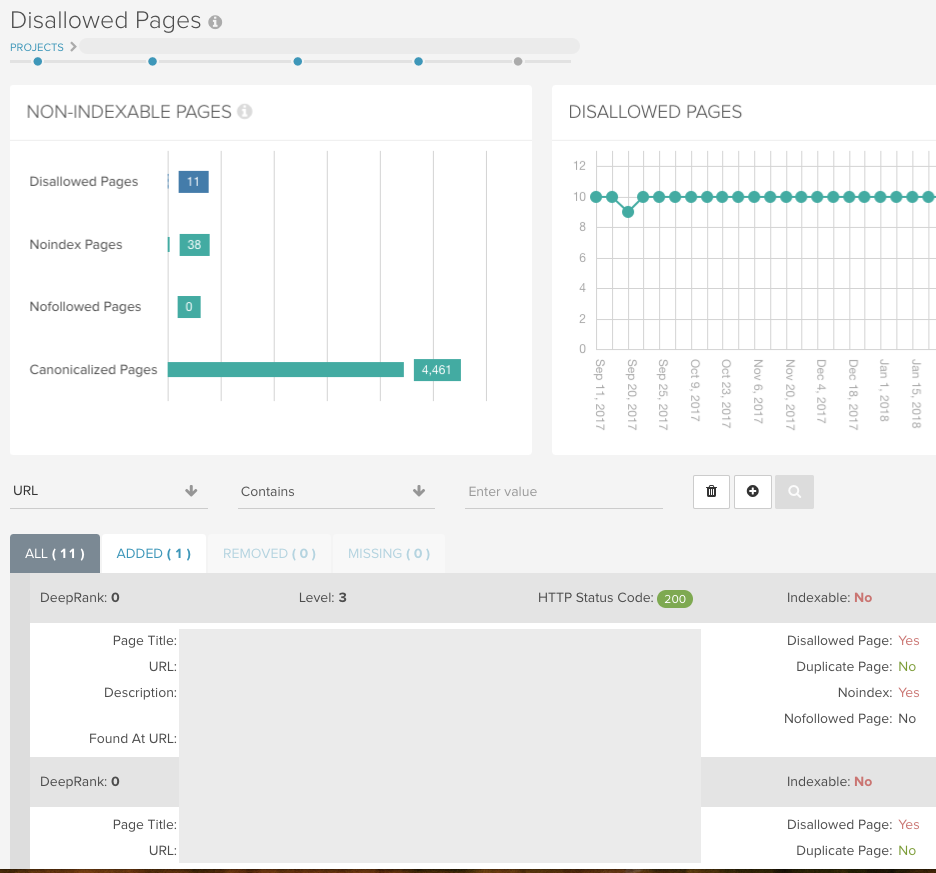
Gebruik onze intuïtieve rapportage in elk van onze rapporten om bepaalde mappen te controleren en patronen in URL’s te ontdekken die u anders misschien zou missen:

Test een nieuw robots.txt bestand met DeepCrawl
Gebruik DeepCrawl’s Robots.txt Overwrite functie in Geavanceerde instellingen om het live bestand te vervangen door een aangepast bestand.

De volgende keer dat u een crawl start, kunt u dan uw testversie gebruiken in plaats van de live versie.
De rapporten Toegevoegde en Verwijderde niet-toegestane URL’s laten dan precies zien welke URL’s zijn beïnvloed door de gewijzigde robots.txt, waardoor evaluatie heel eenvoudig wordt.
Voor meer informatie, lees onze handleiding voor het beheren van robots.txt wijzigingen met DeepCrawl.
Wilt u meer zoals dit?
We hopen dat u dit bericht nuttig vond om meer te leren over noindex, nofollow en disallow om het crawlen van uw site te regelen.
U kunt meer lezen over deze onderwerpen in onze Technische SEO-bibliotheek of als u wilt leren hoe u een technische SEO-audit uitvoert, lees dan onze handleiding.
Bovendien, als je geïnteresseerd bent in het bijhouden van de laatste updates van Google en best practice aanbevelingen dan waarom niet loop jezelf in om onze e-mails?
Loop Me In!
Auteur

Sam Marsden
Sam Marsden is DeepCrawl’s SEO & Content Manager. Sam spreekt regelmatig op marketingconferenties, zoals SMX en BrightonSEO, en levert bijdragen aan industriepublicaties zoals Search Engine Journal en State of Digital.