Le tre parole di cui sopra potrebbero sembrare un gergo SEO, ma sono parole che vale la pena conoscere, poiché capire come usarle significa che puoi dare ordini a Googlebot. Il che è divertente.
Partiamo dalle basi: ci sono tre modi per controllare quali parti del tuo sito i motori di ricerca scansioneranno:
- Noindex: dice ai motori di ricerca di non includere le tue pagine nei risultati di ricerca.
- Disallow: dice loro di non scansionare le tue pagine.
- Nofollow: dice loro di non seguire i link sulla tua pagina.
Cos’è un Meta Tag Noindex?
Un tag ‘noindex’ dice ai motori di ricerca di non includere la pagina nei risultati di ricerca.
Il metodo più comune di noindicizzare una pagina è di aggiungere un tag nella sezione head dell’HTML, o negli header di risposta. Per permettere ai motori di ricerca di vedere queste informazioni, la pagina non deve essere già bloccata (disallowed) in un file robots.txt. Se la pagina è bloccata tramite il file robots.txt, Google non vedrà mai il tag noindex e la pagina potrebbe ancora apparire nei risultati di ricerca.
Per dire ai motori di ricerca di non indicizzare la vostra pagina, aggiungete semplicemente quanto segue alla sezione </head>:
<meta name=”robots” content=”noindex, follow”>
La seconda parte del tag content qui indica che tutti i link di questa pagina dovrebbero essere seguiti, di cui parleremo più avanti.
In alternativa, il tag noindex può essere usato in un X-Robots-Tag nell’intestazione HTTP:
X-Robots-Tag: noindex
Per maggiori informazioni vedere il post di Google Developers sulle specifiche del meta tag Robots e dell’intestazione HTTP X-Robots-Tag.
Come posso usare Noindex in un file Robots.txt?
Anche un tag ‘noindex’ nel vostro file robots.txt dice ai motori di ricerca di non includere la pagina nei risultati di ricerca, ma è un modo più veloce e più facile per noindicare molte pagine in una volta, specialmente se avete accesso al vostro file robots.txt. Per esempio, si potrebbe noindicare tutti gli URL in una cartella specifica.
Ecco un esempio di una direttiva noindex che potrebbe essere inserita nel file robots.txt:
Noindex: /robots-txt-noindexed-page/
Tuttavia, Google consiglia di non usare questo metodo: John Mueller ha dichiarato che “non si dovrebbe fare affidamento su di esso”.
Che cos’è una direttiva Disallow?
Disconoscere una pagina significa che stai dicendo ai motori di ricerca di non scansionarla, il che deve essere fatto nel file robots.txt del tuo sito. È utile se avete molte pagine o file che non servono ai lettori o al traffico di ricerca, perché significa che i motori di ricerca non perderanno tempo a scansionare quelle pagine.

Per aggiungere un disallow, basta aggiungere quanto segue nel vostro file robots.txt:
Disallow: /your-page-url/
Se la pagina ha link esterni o tag canonici che puntano ad essa, potrebbe ancora essere indicizzata e classificata, quindi è importante combinare un disallow con un tag noindex, come descritto di seguito.
Una parola di cautela: disconoscendo una pagina la stai effettivamente rimuovendo dal tuo sito.
Le pagine disconosciute non possono passare PageRank a nessun’altra parte – quindi tutti i link su quelle pagine sono effettivamente inutili dal punto di vista SEO – e disconoscere pagine che dovrebbero essere incluse può avere risultati disastrosi per il tuo traffico, quindi fai molta attenzione quando scrivi le direttive disallow.
Come posso combinare Noindex e Disallow?
Noindex (pagina) + Disallow: Disallow non può essere combinato con noindex sulla pagina, perché la pagina è bloccata e quindi i motori di ricerca non la scansionano per sapere che non devono lasciare la pagina fuori dall’indice.
Noindex (robots.txt) + Disallow: Questo impedisce alle pagine di apparire nell’indice, e impedisce anche che le pagine vengano scansionate. Tuttavia, ricorda che nessun PageRank può passare attraverso questa pagina.
Per combinare un disallow con un noindex nel tuo robots.txt, aggiungi semplicemente entrambe le direttive al tuo file robots.txt:
Disallow: /example-page-1/
Disallow: /esempio-pagina-2/
Noindex: /esempio-pagina-1/
Noindex: /esempio-pagina-2/
Cos’è un tag Nofollow?
Un tag nofollow su un link dice ai motori di ricerca di non usare un link per decidere l’importanza delle pagine collegate (PageRank) o scoprire altri URL all’interno dello stesso sito.
Usi comuni per il nofollow includono link nei commenti e altri contenuti che non si controllano, link a pagamento, embed come widget o infografiche, link in guest post, o qualsiasi cosa fuori tema a cui si vuole comunque collegare la gente.
Storicamente i SEO hanno anche selettivamente nofollowato i link, per incanalare il PageRank interno verso pagine più importanti.
I tag nofollow possono essere aggiunti in uno dei due posti:
- Il <head> della pagina (per nofollow tutti i link su quella pagina): <meta name=”robots” content=”nofollow” />
- il codice del link (per nofollow un singolo link): <a href=”esempio.html” rel=”nofollow”> pagina d’esempio</a>
Un nofollow non impedisce che la pagina collegata venga scansionata completamente; impedisce solo che venga scansionata attraverso quel link specifico. I nostri test, e altri, hanno dimostrato che Google non scansionerà un URL che trova in un link nofollowed.
Google afferma che se un altro sito si collega alla stessa pagina senza usare un tag nofollow o la pagina appare in una Sitemap, la pagina potrebbe ancora apparire nei risultati di ricerca. Allo stesso modo, se si tratta di un URL che i motori di ricerca conoscono già, l’aggiunta di un link nofollow non lo rimuoverà dall’indice.
Nel settembre 2019, Google ha annunciato un aggiornamento alla loro direttiva nofollow e ha introdotto due nuovi attributi di link, questi sono:
- rel=”sponsorizzato” – L’attributo sponsorizzato dovrebbe essere utilizzato per identificare i link che sono a scopo pubblicitario, dove sono presenti accordi di sponsorizzazione e compensazione.
- rel=”ugc” – Come l’attributo per User Generated Content, questo valore è raccomandato per i link all’interno di siti con contenuto generato dall’utente, per esempio i post dei forum e i commenti dei blog.
Inoltre, tutti i link contrassegnati con nofollow, sponsored o ugc sono ora trattati come suggerimenti riguardo a quali link considerare nella ricerca e durante il crawling, al contrario di un semplice segnale, come era usato in precedenza per nofollow. Potete scoprire di più su questo aggiornamento nel nostro post che copre anche l’impatto di questi insieme agli approfondimenti degli esperti.
Che cos’è Noindex Nofollow?
Come detto sopra, l’aggiunta di un tag nofollow a una pagina non impedirà che venga scansionata completamente. Pertanto, per evitare che venga indicizzata, è necessario anche noindicizzare la pagina. Questo permetterà a Google di essere ancora in grado di scansionare la pagina, ma non apparirà nell’indice. Le pagine che probabilmente vorrete noindicizzare includono: pagine di amministrazione/login, risultati di ricerca interna e pagine di registrazione. Per impedire a Google di scansionare completamente la pagina, dovresti anche disabilitarla (vedi sopra).
Altre direttive: Tag canonici, paginazione e Hreflang
Ci sono altri modi per dire a Google e agli altri motori di ricerca come trattare gli URL:
- I tag canonici dicono ai motori di ricerca quale pagina di un gruppo di pagine simili dovrebbe essere indicizzata. Le pagine canonicalizzate (cioè le pagine secondarie che indirizzano i motori di ricerca verso una versione primaria) non sono incluse nell’indice. Se hai un sito mobile e uno desktop separati, dovresti canonicalizzare i tuoi URL mobile a quelli desktop.
- La paginazione raggruppa più pagine insieme in modo che i motori di ricerca sappiano che fanno parte di un insieme. I motori di ricerca dovrebbero dare la priorità alla pagina uno di ogni set quando classificano le pagine, ma tutte le pagine all’interno del set rimarranno nell’indice.
- Hreflang dice ai motori di ricerca quali versioni internazionali dello stesso contenuto sono per quale regione, in modo che possano dare la priorità alla versione corretta per ogni pubblico. Tutte queste versioni rimarranno nell’indice.
Quanto tempo si dovrebbe dedicare alla riduzione del crawl budget?
Potresti sentire un sacco di discorsi sui forum SEO su quanto sia importante l’efficienza della scansione e il crawl budget per il SEO e, mentre è pratica comune disconoscere e non indicizzare grandi gruppi di pagine che non hanno alcun beneficio per i motori di ricerca o i lettori (per esempio, il codice di back-end che viene utilizzato solo per il funzionamento del sito, o alcuni tipi di contenuti duplicati), decidere se nascondere molte pagine individuali non è probabilmente il miglior uso del tempo e degli sforzi.
Google ama indicizzare quanti più URL possibile, quindi, a meno che non ci sia una ragione specifica per nascondere una pagina ai motori di ricerca, di solito va bene lasciare la decisione a Google. In ogni caso, anche se nascondete le pagine ai motori di ricerca, Google continuerà a controllare se quegli URL sono cambiati. Questo è particolarmente pertinente se ci sono link che puntano a quella pagina; anche se Google ha dimenticato l’URL, potrebbe comunque riscoprirlo la prossima volta che viene trovato un link ad esso.
Testare usando Search Console, DeepCrawl e Robotto
Testare robots.txt usando Search Console
Lo strumento robots.txt Tester in Search Console (sotto Crawl) è un modo popolare e largamente efficace per controllare una nuova versione del tuo file per eventuali errori prima che vada live, o testare un URL specifico per vedere se è bloccato:
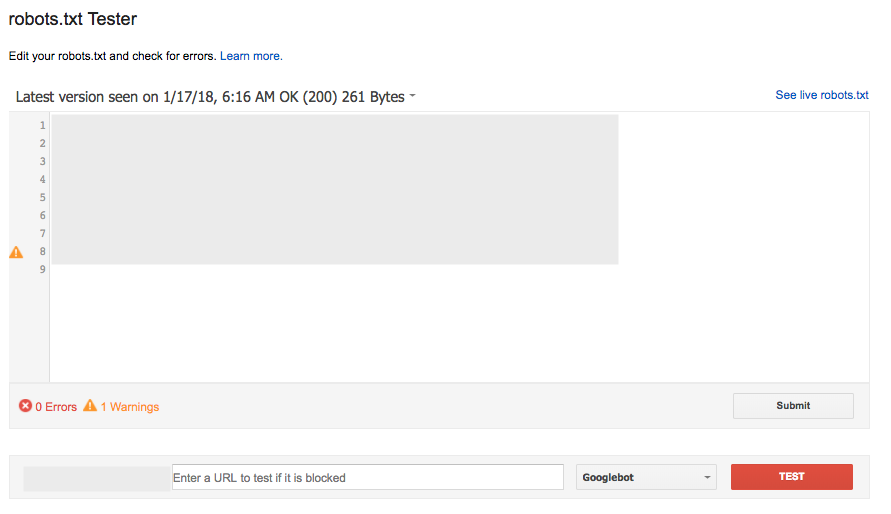
Tuttavia, questo strumento non funziona esattamente allo stesso modo di Google, con alcune sottili differenze nelle regole conflittuali Allow/Disallow che sono della stessa lunghezza.
Lo strumento di test robots.txt li riporta come Consentiti, tuttavia Google ha detto “Se il risultato è indefinito, i valutatori robots.txt possono scegliere di consentire o non consentire la scansione. A causa di ciò, non è consigliabile fare affidamento su uno dei due risultati.”
Per maggiori dettagli, leggete questa discussione del Webmaster Central Help Forum.
Trova tutte le pagine non indicizzabili usando DeepCrawl
Esegui un crawl universale senza restrizioni (ma con le condizioni robots.txt) per consentire a DeepCrawl di restituire tutti i tuoi URL e mostrarti tutte le pagine indicizzabili/non indicizzabili.
Se hai parametri URL che sono stati bloccati da Googlebot usando Search Console, puoi imitare questa impostazione per il tuo crawl usando il campo Rimuovi parametri in Impostazioni avanzate > Riscrittura URL.
Puoi quindi utilizzare i seguenti rapporti per verificare che il sito sia impostato come ti aspetteresti durante la tua prima scansione, e poi combinarli con i log di modifica integrati nelle scansioni successive.
Indexation > Noindex Pages
Questo rapporto vi mostrerà tutte le pagine che contengono un tag noindex nelle meta informazioni, nell’intestazione HTTP o nel file robots.txt.
Indexation > Disallowed Pages
Questo rapporto contiene tutti gli URL che non possono essere scansionati a causa di una regola disallow nel file robots.txt. Ci sono cifre per entrambi i rapporti nella dashboard del tuo rapporto:
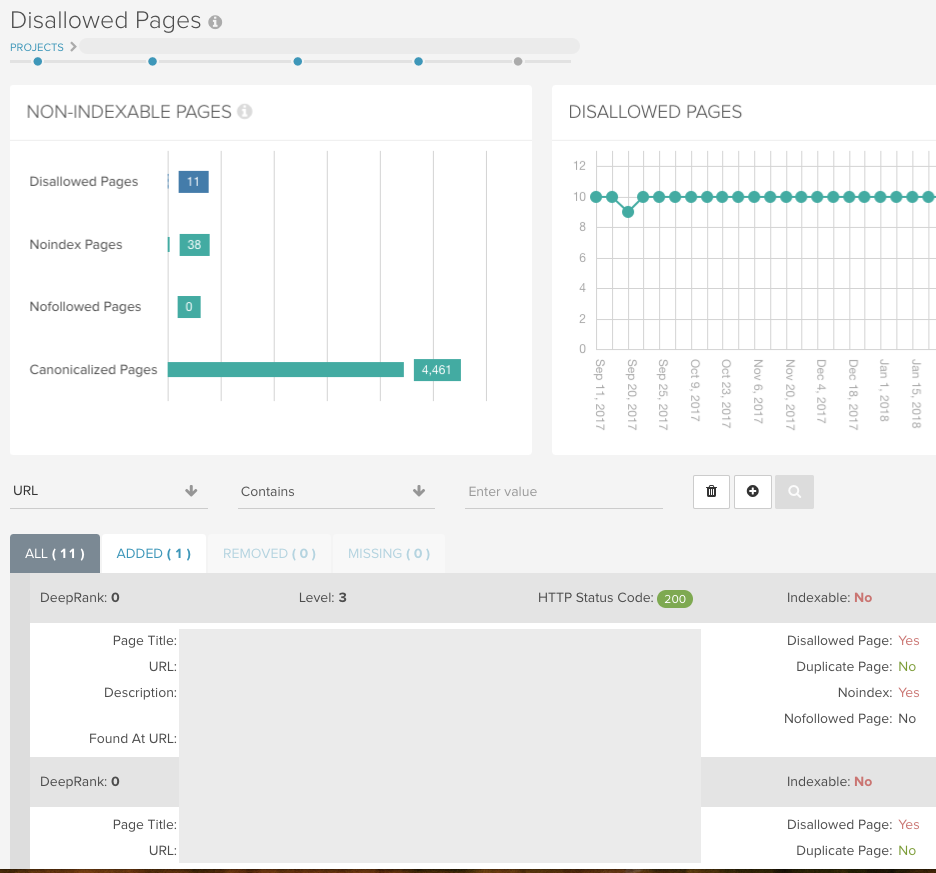
Utilizza la nostra segnalazione intuitiva in ciascuno dei nostri rapporti per controllare cartelle particolari e individuare modelli di URL che altrimenti potrebbero sfuggirti:

Testa un nuovo file robots.txt utilizzando DeepCrawl
Utilizza la funzione Robots.txt di DeepCrawl in Impostazioni avanzate per sostituire il file live con uno personalizzato.

Si può quindi utilizzare la versione di prova al posto di quella live la prossima volta che si avvia una scansione.
I rapporti Added e Removed Disallowed URLs mostreranno esattamente quali URLs sono stati influenzati dal robots.txt, rendendo la valutazione molto semplice.
Per maggiori informazioni, leggi la nostra guida alla gestione delle modifiche di robots.txt con DeepCrawl.
Vuoi altro come questo?
Speriamo che tu abbia trovato questo post utile per saperne di più su noindex, nofollow e disallow per controllare il crawling del tuo sito.
Puoi leggere di più su questi argomenti nella nostra Technical SEO Library o se vuoi imparare come condurre un audit SEO tecnico leggi la nostra guida.
Inoltre, se sei interessato a stare al passo con gli ultimi aggiornamenti di Google e le raccomandazioni sulle migliori pratiche, perché non ti iscrivi alle nostre e-mail?
Mettimi in loop!
Autore

Sam Marsden
Sam Marsden è il SEO & Content Manager di DeepCrawl. Sam parla regolarmente alle conferenze di marketing, come SMX e BrightonSEO, e contribuisce a pubblicazioni di settore come Search Engine Journal e State of Digital.