Cet article a été évalué par les pairs du Journal of Electronic Publishing.
Toutes les langues amérindiennes parlées aujourd’hui s’écrivent soit dans un alphabet latin quelconque, augmenté de lettres « accentuées », soit dans un syllabaire, ensemble de symboles syllabiques indivisibles, dont chacun représente une syllabe. Les langues apache et navaho font partie des langues amérindiennes qui utilisent un alphabet latin, tandis que le cherokee, l’inuiktitut et le cri font partie des langues qui utilisent des syllabaires modernes. Les syllabaires, courants dans les écritures anciennes, étaient utilisés par les Mayas et les Epi-Olmèques de Méso-Amérique.
Parce qu’un syllabaire est moins expressif qu’une écriture alphabétique, il peut être transcrit dans une écriture alphabétique sans perdre de sens. Les étudiants de la langue cherokee apprennent une transcription latine du syllabaire pour faciliter l’apprentissage du cherokee. Les mêmes caractéristiques qui permettent de transcrire le cherokee dans l’alphabet latin permettent de créer des outils de composition pour les syllabaires. Un outil de composition moderne conçu pour traiter les syllabaires devrait permettre aux utilisateurs de taper les symboles soit directement (par exemple, en utilisant un éditeur Unicode si l’écriture est prise en charge par la norme Unicode, ou par un éditeur qui prend en charge un jeu de caractères spéciaux), soit en utilisant une transcription latine standard. (Unicode fournit un numéro unique lisible par ordinateur – appelé point de code – pour chaque caractère ; ce numéro fonctionne sur toutes les plates-formes, programmes et langues.)
Cet article porte sur Omega, un système de composition moderne basé sur TeX, qui accepte par défaut les fichiers texte Unicode, mais qui est capable de traiter tout encodage d’entrée imaginable. En outre, il introduit un certain nombre de fonctionnalités qui facilitent la vie des concepteurs d’outils. J’ai utilisé ces fonctionnalités pour développer un certain nombre d’outils qui facilitent la préparation de documents en langues cherokee et inuktitut.
TeX et LaTeX
TeX est un programme informatique légendaire conçu par Donald E. Knuth, le célèbre professeur d’informatique de l’université de Stanford. C’est un moteur de composition numérique, un programme informatique qui fait le travail d’un typographe, en décrivant l’apparence de la page imprimée (Knuth, 1993). TeX traite un fichier d’entrée qui contient à la fois du texte et des commandes de composition. Leslie Lamport a conçu le langage de balisage LaTeX (Lamport, 1994) qui se place au-dessus du moteur de composition TeX pour faciliter la création de fichiers d’entrée. Comme de nombreuses personnes connaissent LaTeX mais ignorent sa relation avec TeX, elles pensent à tort que LaTeX et TeX sont deux programmes différents. Pourtant, TeX produit un fichier indépendant du périphérique (DVI) décrivant le texte et les éléments graphiques d’une page qui peut être traité ultérieurement pour générer d’autres langages de description de page tels que la sortie PostScript. Knuth a également conçu METAFONT, qui met en œuvre un langage de description et de génération de polices différent (Knuth, 1992).
Bien que le développement de TeX ait été gelé depuis que Knuth a décidé de ne plus développer TeX et METAFONT, de nouveaux moteurs de composition qui étendent les capacités de TeX continuent d’apparaître. Les extensions de TeX les plus notables sont : pdfTeX (Thanh et al., 1999), qui peut produire directement des fichiers PDF ; e-TeX (NTS Team et Beiettenlohner, 1998), qui est une extension de TeX qui augmente la capacité et les possibilités de TeX en permettant la composition bidirectionnelle ; et Omega qui est l’extension Unicode de TeX capable de prendre une entrée Unicode et de la composer dans de nombreux sens d’écriture (Syropoulos et al., 2002). En outre, Omega peut produire du contenu XML et MathML. Notez que MathML est une application XML qui vise principalement à faciliter l’utilisation et la réutilisation du contenu mathématique et scientifique sur le Web. Avec Omega, un compositeur peut écrire des préprocesseurs qui relient Unicode et composition. (Notez que Lambda est un surnom pour LaTeX lorsqu’il est utilisé avec Omega.)
Cherokee
Le cherokee est une langue iroquoise parlée par quelque 20 000 personnes, principalement comme langue seconde. Il ne reste que deux dialectes : L’Oklahoma (parlé par environ 17 000 personnes) et la Caroline du Nord (parlé par les 3 000 autres personnes).
L’écriture cherokee a été développée au 19ème siècle par un Cherokee nommé  Sequoya (qui utilisait le nom de George Guess ou George Giss lorsqu’il traitait avec les hommes blancs). Certains pensent que Sequoya est la seule personne à avoir développé une écriture seule, mais d’autres l’ont fait. Par exemple : le Grec Saint-Clément d’Ohrid a développé l’écriture cyrillique (Kirilitsa), sous une forme proche de celle encore utilisée aujourd’hui, à partir des travaux antérieurs des moines grecs Saint-Cyrille ; Saint-Méthode a développé une écriture slave appelée Glagolitsa ; le révérend James Evans a créé le système d’écriture de la langauge inuktitut à partir de travaux antérieurs sur la langue crie, qui, à son tour, était basée sur des travaux sur la langue ojibway ; et Afaka Atumisi a inventé le syllabaire Ndjuka.
Sequoya (qui utilisait le nom de George Guess ou George Giss lorsqu’il traitait avec les hommes blancs). Certains pensent que Sequoya est la seule personne à avoir développé une écriture seule, mais d’autres l’ont fait. Par exemple : le Grec Saint-Clément d’Ohrid a développé l’écriture cyrillique (Kirilitsa), sous une forme proche de celle encore utilisée aujourd’hui, à partir des travaux antérieurs des moines grecs Saint-Cyrille ; Saint-Méthode a développé une écriture slave appelée Glagolitsa ; le révérend James Evans a créé le système d’écriture de la langauge inuktitut à partir de travaux antérieurs sur la langue crie, qui, à son tour, était basée sur des travaux sur la langue ojibway ; et Afaka Atumisi a inventé le syllabaire Ndjuka.
 Syllabaire cherokee
Syllabaire cherokee Inuktitut
L’inuktitut est la langue des Inuits (également appelés « Esquimaux », mais ce terme est considéré comme offensant par les Inuits qui vivent au Canada et au Groenland). La langue est parlée par environ 152 000 personnes au Groenland, au Canada, en Alaska et dans le district autonome de Chukotka, qui est situé dans la région extrême nord-est de la Fédération de Russie. L’écriture syllabique inuktitut est utilisée par les Inuits qui vivent au Canada, notamment dans le nouveau territoire canadien du Nunavut. Ce système d’écriture a été inventé par le révérend James Evans, un missionnaire wesleyen. Le tableau ci-dessous présente l’écriture syllabique inuktitut et la transcription latine des symboles inuktitut. (Notez que l’écriture Inuktitut est supportée par Unicode et qu’elle fait en fait partie de la section Syllabique autochtone canadienne unifiée de la norme Unicode.)
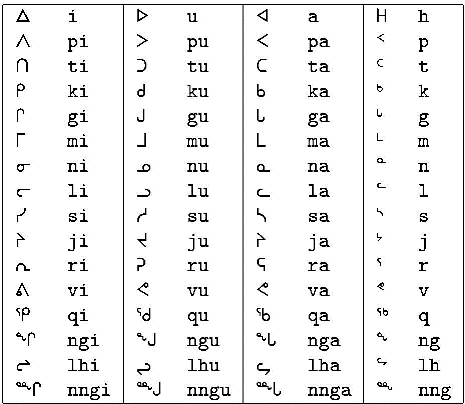 Syllabaire inuktitut
Syllabaire inuktitut Actuellement, il existe deux orthographes inuktitut (l’orthographe est l’art ou l’étude de l’orthographe correcte selon l’usage établi) : l’anglicane (utilisée principalement au Nunavut) et la catholique (utilisée principalement au Québec). Elles diffèrent dans la manière d’écrire les voyelles « longues », c’est-à-dire les syllabes comportant deux voyelles identiques. L’orthographe anglicane place un point au-dessus d’une syllabe courte pour la rendre longue ; l’orthographe catholique utilise deux symboles. Notez les différentes représentations du mot « ataata » (père) ci-dessous.
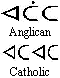 « ataata » (père) dans les orthographes inuktitut
« ataata » (père) dans les orthographes inuktitut Mise en page des syllabaires avec Lambda
Les outils de mise en page que j’ai conçus pour les textes cherokee et inuktitut peuvent être utilisés avec le système de mise en page Omega, car ils reposent fortement sur les processus de traduction Omega (OmegaTP). Techniquement, un OmegaTP est un automate déterministe à états finis (une « machine » abstraite – une fonction mathématique – utilisée dans l’étude du calcul et des langues) qui est utilisé pour transformer un flux de caractères d’entrée. Par exemple, un OmegaTP peut transformer un flux de caractères d’entrée ISO-Latin-1 en un flux de caractères UCS-2. Bien que nous puissions obtenir exactement le même effet en utilisant un préprocesseur externe et TeX, les préprocesseurs sont particulièrement difficiles à utiliser. Nous avons donc construit un système qui ne nécessiterait pas de préprocesseur.
D’abord, nous avons dû identifier le codage valide pour le texte Cherokee ou Inuktiut. Nous avons déterminé que puisque les deux syllabaires sont supportés par la norme Unicode, nous autoriserions les fichiers d’entrée Unicode (soit UCS-2, soit UTF-8). Puisque les deux syllabaires ont des transcriptions latines standard, nous avons décidé de les autoriser également. Enfin, il existe un certain nombre de jeux de caractères à huit bits pour l’inuktitut, nous en avons donc choisi un. Pour travailler avec les entrées Unicode, nous avons utilisé des polices virtuelles codées en Unicode. Une police virtuelle est un mécanisme par lequel nous créons une police qui dessine réellement les glyphes des polices existantes. Pour créer une nouvelle police virtuelle, nous devons construire un fichier de liste de propriétés virtuelles, qui décrit les glyphes virtuels de la police, qui sont tirés de polices réelles, ainsi que leurs dimensions, les paires de crénage et les paires de ligatures. En outre, les polices virtuelles sont utilisées pour créer de nouveaux glyphes tels que des lettres accentuées, des glyphes soulignés, etc.
Pour le cherokee, Omega utilise une version PostScript de la police TrueType Cherokee officielle développée par Tonia Williams de la nation Cherokee de l’Oklahoma, qui ne contient aucun glyphe latin et ne suit pas le système de numérotation de Sequoya. Pour la langue inuktitut, il utilise une version PostScript de la police TrueType Nunacom développée par Nortext, une société canadienne qui a été la première à créer des polices de caractères pour les langues autochtones au début des années 1980. Les polices virtuelles pour la langue inuktitut tirent des glyphes de la police Nunacom, des polices standard Computer Modern qui accompagnent chaque installation TeX, et d’une police que j’ai fabriquée, pour compléter les polices de la distribution TeX standard.
Pour le script cherokee, nous n’avons dû concevoir qu’un seul OmegaTP, car il n’existe pas, à notre connaissance, de codepage cherokee 8 bits. La conception de l’OmegaTP était presque simple, à l’exception d’un problème simple : la gestion de la syllabe qui se produit lorsqu’un » s » n’est pas suivi d’un » a « , » e « , » i « , » o « , » u » ou » v « . OmegaTP « repousse » le caractère qui suit immédiatement le « s ». Sinon, nous générons simplement le symbole correspondant. Par exemple, si la tête du flux d’entrée est « se », OmegaTP renverra le caractère 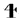 et ainsi de suite. Par exemple, l’entrée « elohinodohiyigesesti » (paix sur la Terre) sera composée comme suit
et ainsi de suite. Par exemple, l’entrée « elohinodohiyigesesti » (paix sur la Terre) sera composée comme suit
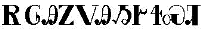
La composition de l’inuktitut avec Lambda est plus complexe que la composition du cherokee parce que nous avons en fait une transcription latine qui peut produire différents résultats, selon l’orthographe supposée, et une page de code de huit bits valide. Nous avons donc dû coder trois OmegaTP pour traiter tous les cas possibles. En outre, nous devions offrir aux utilisateurs la possibilité de choisir la méthode d’entrée de manière transparente. Nous proposons donc les options suivantes : « nunavut », « quebec » et « inscii ». Nous avons rencontré beaucoup des mêmes problèmes avec l’inuktitut qu’avec le cherokee, comme les caractères qui peuvent soit être autonomes, soit commencer une syllabe. Le tableau ci-dessous montre la disposition du jeu de caractères ISCII qui correspond aux outils OmegaTP.
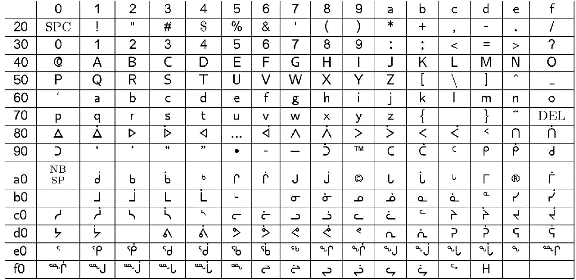 Jeu de caractères ISCII
Jeu de caractères ISCII Puisqu’Omega peut effectuer la césure des mots si on lui donne des instructions, nous avons codé les règles de césure de la langue inuktitut afin que les outils soient complets.
Omega et les autres langues amérindiennes
En plus des langues cherokee et inuktitut, les langues pied-noir, déné (porteur), cri et naskapi utilisent une écriture non latine. Leurs écritures sont incluses dans le fichier PDF intitulé Unified Canadian Aboriginal Syllabics section of the Unicode Standard. Par conséquent, sur la base de notre expérience antérieure, il est assez simple de créer des outils similaires. Cependant, nous pensons qu’il serait préférable de créer un ensemble d’outils pouvant être utilisés pour la composition de toute langue américaine n’utilisant pas l’écriture latine. Cela peut sembler assez restrictif, mais les outils qui sont disponibles aujourd’hui sont tout à fait adéquats pour traiter les langues américaines qui utilisent l’écriture latine.
Bien sûr, il y a quelques langues qui utilisent l’écriture latine, comme le Smalgyax et le Tlingit, qui ont quelques lettres spéciales (par exemple, des lettres soulignées), et la langue Apache, qui a quelques lettres qui sont communes dans certaines langues européennes, mais le texte dans ces langues peut être traité avec des outils qui sont déjà largement disponibles. Par exemple, la phrase Tlingit 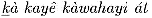 (droits), la phrase Smalgyax
(droits), la phrase Smalgyax 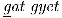 (droits), et le mot Apache
(droits), et le mot Apache  (poisson) et
(poisson) et 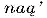 (maïs), ont été composés avec ces méthodes standard. Bien sûr, il est possible de créer des polices virtuelles spéciales qui contiendront toutes ces lettres latines spéciales (Syropoulous et al., 2002).
(maïs), ont été composés avec ces méthodes standard. Bien sûr, il est possible de créer des polices virtuelles spéciales qui contiendront toutes ces lettres latines spéciales (Syropoulous et al., 2002).
La situation est assez différente lorsqu’il s’agit de la composition d’anciennes écritures américaines telles que les écritures épi-olmèque et maya. Tout d’abord, les symboles de ces écritures ne sont pas définis dans la norme Unicode. En outre, le sens d’écriture n’est pas occidental (c’est-à-dire de gauche à droite et de haut en bas de la page), mais identique à celui de l’écriture mongole ouïgoure classique (c’est-à-dire de haut en bas et de gauche à droite de la page). Nous travaillons sur un outil qui permettra aux chercheurs de composer les quelques textes Epi-Olmec disponibles. Une police Epi-Olmec est presque prête. La police elle-même est basée sur la description de l’écriture telle que présentée dans Epi-Olmec Hieroglyphic Writing. Comme l’écriture est en gros un syllabaire, nous avons créé un OmegaTP simple qui peut gérer un sous-ensemble du syllabaire, mais nous avons constaté que les commandes qui peuvent être utilisées pour définir la direction de l’écriture ne fonctionnent pas bien avec notre police. Nous avons donc dû améliorer l’OmegaTP pour qu’il produise réellement une commande de composition et pas seulement une traduction. Pour voir la différence, considérez les exemples suivants :
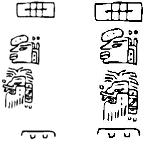
Les symboles de gauche ont été composés en s’appuyant simplement sur les capacités d’Omega ; ceux de droite ont été composés en utilisant un OmegaTP amélioré. Bien sûr, il reste beaucoup de travail à faire et nous ne pensons donc pas que les outils seront disponibles de sitôt.
Conclusions et travaux futurs
Nous avons présenté les outils que nous avons développés pour la composition de textes cherokee et inuktitut. Ces outils sont disponibles gratuitement auprès du Comprehensive TeX Archive Network (CTAN) à ftp://ftp.dante.de ou ftp://ftp.tex.ac.uk ou directement auprès de moi. Il y a encore beaucoup de travail à faire sur ces outils – en particulier sur l’outil Cherokee – mais ils peuvent être utilisés comme modèle pour créer de nouveaux outils pour d’autres besoins de composition. Comme les prochaines versions d’Omega seront capables de comprendre les substituts Unicode, il sera même possible d’appliquer les idées présentées ici au problème de la composition de textes musicaux byzantins et occidentaux.

Apostolos Syropoulos, président et membre fondateur du Greek TeX Friends Group, a écrit plusieurs paquets LaTeX pour faciliter la composition en langue grecque avec LaTeX. Il est l’auteur du premier livre sur LaTeX en grec, LATEX. Il est co-auteur de TEX and Electronic Typesetting : 110 Questions and Answers, la FAQ grecque pour TeX, LaTeX, METAFONT et les polices en général. Il est titulaire d’un B.Sc. en physique, d’un M.Sc. en informatique et d’un doctorat en informatique théorique. Il travaille actuellement à la rédaction de livres sur LaTeX et la typographie numérique et sur la programmation en Perl. Il a écrit de nombreux articles sur l’informatique en général et la typographie en particulier. Ses intérêts scientifiques comprennent la théorie des langages de programmation, la concurrence, la logique (en particulier la logique linéaire et la logique floue) et la composition électronique avec TEX. Il peut programmer en Pascal, FORTRAN, Perl, Modula-2, C/C++, LML, SML, Prolog et Java, et il parle grec, anglais, un peu de suédois et un peu de russe. Son site Web se trouve à l’adresse http://obelix.ee.duth.gr/~apostolo/. On peut le joindre par courriel à [email protected].
Knuth, D.E. (1992). The Metafont Book. Volume C de Computers and Typesetting. Reading, MA : Addison-Wesley.
Knuth, D.E. (1993). The TeX Book. Volume A de Computers and Typesetting. Reading, MA : Addison-Wesley.
Lamport, L. (1994). LaTeX : Un système de préparation de documents, 2e éd. Addison-Wesley.
L’équipe NTS et Beiettenlohner, P. (1998). Le manuel e-TeX, version 2. MAPS, 20, 1998, 248-263.
Syropoulos, A., Tsolomitis, A., et Sofroniou, N. (2002). La typographie numérique à l’aide de LaTeX. New York : Springer-Verlag.
Thanh, H.T., Rahtz, S., et Hagen, H. (1999). Le manuel des utilisateurs de pdfTeX. MAPS, 22, 1999, 94-114.
Liens de cet article
Comprehensive TeX Archive Network (CTAN), http://www.ctan.org
Donald E. Knuth, http://www-cs-faculty.stanford.edu/~knuth
Epi-Olmec Hieroglyphic Writing, http://www.albany.edu/anthro/maldp/papers.htm
Nortext, http://www.nortext.com
Oklahoma Cherokee Nation, http://www.cherokee.org
Norme Unicode, http://www.unicode.org
Section syllabique autochtone canadienne unifiée de la norme Unicode, http://www.unicode.org/charts/PDF/U1400.pdf