Las tres palabras anteriores pueden sonar a jerigonza de SEO, pero son palabras que vale la pena conocer, ya que entender cómo usarlas significa que puedes dar órdenes a Googlebot. Lo cual es divertido.
Así que empecemos por lo básico: hay tres formas de controlar qué partes de tu sitio rastrearán los motores de búsqueda:
- Noindex: le dice a los motores de búsqueda que no incluyan tu(s) página(s) en los resultados de búsqueda.
- Disallow: les dice que no rastreen tu(s) página(s).
- Nofollow: les dice que no sigan los enlaces de tu página.
¿Qué es una etiqueta Meta Noindex?
Una etiqueta ‘noindex’ le dice a los motores de búsqueda que no incluyan la página en los resultados de búsqueda.
El método más común para noindexar una página es añadir una etiqueta en la sección head del HTML, o en las cabeceras de respuesta. Para permitir que los motores de búsqueda vean esta información, la página no debe estar ya bloqueada (no permitida) en un archivo robots.txt. Si la página está bloqueada a través de su archivo robots.txt, Google nunca verá la etiqueta noindex y la página podría seguir apareciendo en los resultados de búsqueda.
Para indicar a los motores de búsqueda que no indexen tu página, simplemente añade lo siguiente a la sección </head>:
<meta name=»robots» content=»noindex, follow»>
La segunda parte de la etiqueta de contenido aquí indica que todos los enlaces de esta página deben ser seguidos, lo que discutiremos a continuación.
Alternativamente, la etiqueta noindex puede utilizarse en una etiqueta X-Robots en la cabecera HTTP:
Etiqueta X-Robots: noindex
Para más información, consulte el post de Google Developers sobre las especificaciones de la metaetiqueta Robots y la cabecera HTTP X-Robots.
¿Cómo puedo utilizar Noindex en un archivo Robots.txt
Una etiqueta ‘noindex’ en su archivo robots.txt también indica a los motores de búsqueda que no incluyan la página en los resultados de búsqueda, pero es una forma más rápida y sencilla de noindexar muchas páginas a la vez, especialmente si tiene acceso a su archivo robots.txt. Por ejemplo, podría noindexar cualquier URL de una carpeta específica.
Aquí tiene un ejemplo de directiva noindex que podría colocarse en el archivo robots.txt:
Noindex: /robots-txt-noindexed-page/
Sin embargo, Google desaconseja utilizar este método: John Mueller ha declarado que «no deberías confiar en él».
¿Qué es una directiva Disallow?
Descargar una página significa que estás diciendo a los motores de búsqueda que no la rastreen, lo que debe hacerse en el archivo robots.txt de tu sitio. Es útil si tiene muchas páginas o archivos que no son útiles para los lectores o el tráfico de búsqueda, ya que significa que los motores de búsqueda no perderán tiempo rastreando esas páginas.

Para añadir un disallow, simplemente añada lo siguiente en su archivo robots.txt:
Disallow: /su-página-url/
Si la página tiene enlaces externos o etiquetas canónicas que apuntan a ella, podría seguir siendo indexada y clasificada, por lo que es importante combinar un disallow con una etiqueta noindex, tal y como se describe a continuación.
Una advertencia: al desautorizar una página la está eliminando efectivamente de su sitio.
Las páginas desautorizadas no pueden pasar PageRank a ninguna otra parte – por lo que cualquier enlace en esas páginas es efectivamente inútil desde una perspectiva SEO – y desautorizar páginas que se supone que están incluidas puede tener resultados desastrosos para su tráfico, así que tenga mucho cuidado al escribir directivas disallow.
¿Cómo puedo combinar Noindex y Disallow?
Noindex (página) + Disallow: Disallow no se puede combinar con noindex en la página, porque la página está bloqueada y por lo tanto los motores de búsqueda no la rastrearán para saber que no deben dejar la página fuera del índice.
Noindex (robots.txt) + Disallow: Esto evita que las páginas aparezcan en el índice, y también evita que las páginas sean rastreadas. Sin embargo, recuerde que ningún PageRank puede pasar por esta página.
Para combinar un disallow con un noindex en su robots.txt, simplemente añada ambas directivas a su archivo robots.txt:
Disallow: /ejemplo-página-1/
Disallow: /ejemplo-página-2/
Noindex: /ejemplo-página-1/
Noindex: /ejemplo-página-2/
¿Qué es una etiqueta nofollow?
Una etiqueta nofollow en un enlace indica a los motores de búsqueda que no utilicen un enlace para decidir sobre la importancia de las páginas enlazadas (PageRank) o descubrir más URLs dentro del mismo sitio.
Los usos comunes de los nofollows incluyen enlaces en comentarios y otros contenidos que no controlas, enlaces pagados, incrustaciones como widgets o infografías, enlaces en posts de invitados, o cualquier cosa fuera del tema que aún quieres enlazar a la gente.
Históricamente los SEOs también han hecho nofollow selectivamente a los enlaces, para canalizar el PageRank interno a las páginas más importantes.
Las etiquetas nofollow se pueden añadir en uno de estos dos lugares:
- El <head> de la página (para hacer nofollow a todos los enlaces de esa página): <meta name=»robots» content=»nofollow» />
- El código del enlace (para nofollow un enlace individual): <a href=»ejemplo.html» rel=»nofollow»>página de ejemplo</a>
- rel=»patrocinado» – El atributo patrocinado debe utilizarse para identificar los enlaces que tienen fines publicitarios, donde existen acuerdos de patrocinio y compensación.
- rel=»ugc» – Como el atributo de contenido generado por el usuario, este valor se recomienda para los enlaces dentro de los sitios de contenido generado por el usuario, por ejemplo, los mensajes del foro y los comentarios del blog.
- Las etiquetas canónicas indican a los motores de búsqueda qué página de un grupo de páginas similares debe ser indexada. Los canonicalizados (es decir, las páginas secundarias que dirigen a los motores de búsqueda hacia una versión primaria) no se incluyen en el índice. Si tiene sitios móviles y de escritorio separados, se supone que debe canonizar sus URLs móviles a las de escritorio.
- La paginación agrupa varias páginas para que los motores de búsqueda sepan que forman parte de un conjunto. Los motores de búsqueda deben dar prioridad a la página uno de cada conjunto a la hora de clasificar las páginas, pero todas las páginas del conjunto permanecerán en el índice.
- Hreflang indica a los motores de búsqueda qué versiones internacionales del mismo contenido son para cada región, de modo que puedan dar prioridad a la versión correcta para cada público. Todas estas versiones permanecerán en el índice.
Un nofollow no impedirá que la página enlazada sea rastreada por completo; sólo impide que sea rastreada a través de ese enlace específico. Nuestras propias pruebas, y otras, han demostrado que Google no rastreará una URL que encuentre en un enlace nofollow.
Google afirma que si otro sitio enlaza a la misma página sin utilizar una etiqueta nofollow o la página aparece en un sitemap, la página podría seguir apareciendo en los resultados de búsqueda. Del mismo modo, si se trata de una URL que los motores de búsqueda ya conocen, añadir un enlace nofollow no la eliminará del índice.
En septiembre de 2019, Google anunció una actualización de su directiva nofollow e introdujo dos nuevos atributos de enlace, estos son:
Además, todos los enlaces marcados con nofollow, patrocinado o ugc se tratan ahora como pistas sobre los enlaces que se deben tener en cuenta en la búsqueda y al rastrear, en lugar de ser sólo una señal, como se utilizaba anteriormente para nofollow. Puedes encontrar más información sobre esta actualización en nuestro post que también cubre el impacto de estos junto con las opiniones de los expertos.
¿Qué es Noindex Nofollow?
Como se ha mencionado anteriormente, añadir una etiqueta nofollow a una página no impedirá que sea rastreada por completo. Por lo tanto, para evitar que se indexe, también tendrá que noindexar la página. De este modo, Google podrá seguir rastreando la página, pero no aparecerá en el índice. Entre las páginas que probablemente querrá desindexar se encuentran las páginas de administración e inicio de sesión, los resultados de la búsqueda interna y las páginas de registro. Para evitar que Google rastree la página por completo, también debe desautorizarla (ver arriba).
Otras directivas: Etiquetas canónicas, paginación y Hreflang
Hay otras formas de indicar a Google y a otros motores de búsqueda cómo tratar las URL:
¿Cuánto tiempo debe dedicar a reducir el presupuesto de rastreo?
Puede que oigas hablar mucho en los foros de SEO sobre lo importante que es la eficiencia del rastreo y el crawl budget para el SEO y, aunque es una práctica común desautorizar y noindexar grandes grupos de páginas que no tienen ningún beneficio para los motores de búsqueda o los lectores (por ejemplo, el código del back-end que sólo se utiliza para el funcionamiento del sitio, o algunos tipos de contenido duplicado), decidir si ocultar muchas páginas individuales probablemente no sea el mejor uso del tiempo y el esfuerzo.
A Google le gusta indexar tantas URLs como sea posible, así que, a menos que haya una razón específica para ocultar una página de los motores de búsqueda, normalmente está bien dejar la decisión a Google. En cualquier caso, aunque oculte páginas a los motores de búsqueda, Google seguirá comprobando si esas URL han cambiado. Esto es especialmente pertinente si hay enlaces que apuntan a esa página; incluso si Google se ha olvidado de la URL, podría volver a descubrirla la próxima vez que se encuentre un enlace a ella de todos modos.
Pruebas con Search Console, DeepCrawl y Robotto
Pruebas de robots.txt con Search Console
La herramienta robots.txt en Search Console (bajo Crawl) es una forma popular y muy efectiva de comprobar una nueva versión de su archivo para cualquier error antes de que se ponga en marcha, o probar una URL específica para ver si está bloqueada:
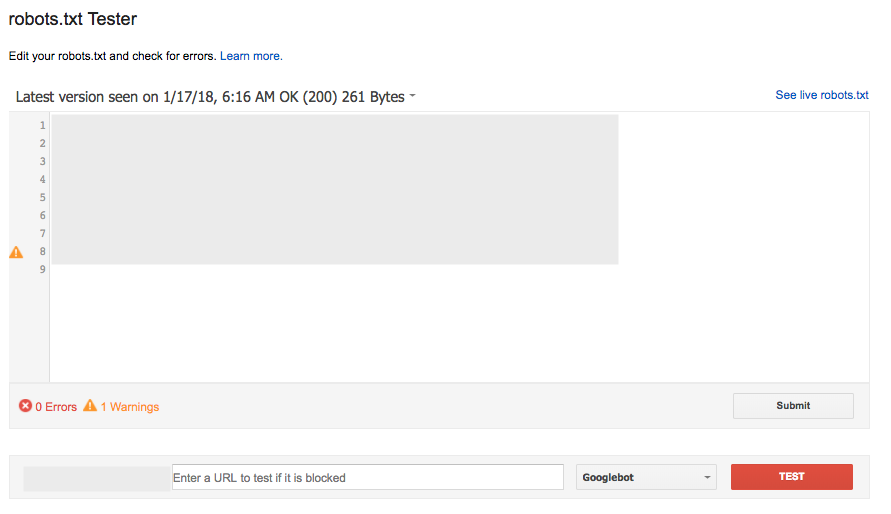
Sin embargo, esta herramienta no funciona exactamente de la misma manera que Google, con algunas diferencias sutiles en las reglas Allow/Disallow conflictivas que tienen la misma longitud.
La herramienta de comprobación de robots.txt informa de que están permitidas, sin embargo, Google ha dicho que «si el resultado es indefinido, los evaluadores de robots.txt pueden optar por permitir o no permitir el rastreo». Por ello, no se recomienda confiar en que cualquiera de los dos resultados se utilice de forma generalizada.’
Para obtener más detalles, lea este debate del Foro de ayuda para webmasters de Google.
Encuentre todas las páginas no indexables mediante DeepCrawl
Ejecute un rastreo universal sin ninguna restricción (pero con las condiciones de robots.txt) para permitir que DeepCrawl devuelva todas sus URLs y le muestre todas las páginas indexables/no indexables.
Si tiene parámetros de URL que han sido bloqueados a Googlebot utilizando Search Console, puede imitar esta configuración para su rastreo utilizando el campo Eliminar parámetros en Configuración avanzada > Reescritura de URL.
A continuación, puede utilizar los siguientes informes para comprobar que el sitio está configurado como se espera en su primer rastreo, y luego combinarlos con los registros de cambios incorporados en los rastreos posteriores.
Indexación > Páginas no indexadas
Este informe le mostrará todas las páginas que contienen una etiqueta noindex en la metainformación, la cabecera HTTP o el archivo robots.txt.
Indexación > Páginas no permitidas
Este informe contiene todas las URL que no se pueden rastrear debido a una regla de desautorización en el archivo robots.txt. Hay cifras para estos dos informes en el panel de control de su informe:
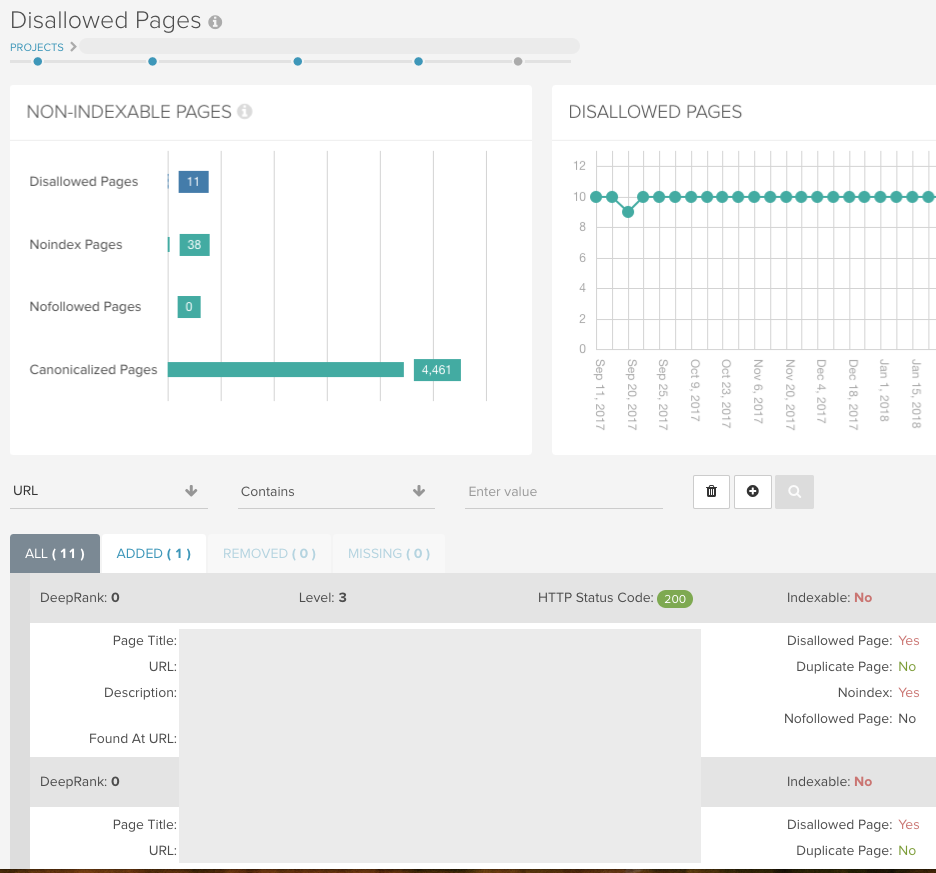
Utilice nuestros informes intuitivos en cada uno de nuestros informes para comprobar carpetas concretas y detectar patrones en las URL que de otro modo podría pasar por alto:

Prueba un nuevo archivo robots.txt con DeepCrawl
Utilice la función Robots.txt de DeepCrawl en la configuración avanzada para reemplazar el archivo en vivo con uno personalizado.

A continuación, puede utilizar su versión de prueba en lugar de la versión en vivo la próxima vez que inicie un rastreo.
Los informes de URLs añadidas y eliminadas no permitidas mostrarán exactamente las URLs afectadas por los robots.txt, lo que hace que la evaluación sea muy sencilla.
Para obtener más información, lea nuestra guía sobre la gestión de los cambios de robots.txt con DeepCrawl.
¿Quiere más como esto?
Esperamos que este post te haya resultado útil para aprender más sobre noindex, nofollow y disallow para controlar el rastreo de tu sitio.
Puedes leer más sobre estos temas en nuestra Biblioteca de SEO Técnico o si quieres aprender a realizar una auditoría de SEO técnico ten una lectura de nuestra guía.
Además, si está interesado en mantenerse al día con las últimas actualizaciones de Google y las recomendaciones de mejores prácticas, ¿por qué no se conecta a nuestros correos electrónicos?
¡Envíame!
Autor

Sam Marsden
Sam Marsden es el Director de Contenido SEO de DeepCrawl &. Sam habla regularmente en conferencias de marketing, como SMX y BrightonSEO, y es colaborador de publicaciones del sector como Search Engine Journal y State of Digital.