Die drei oben genannten Wörter mögen wie SEO-Kauderwelsch klingen, aber sie sind wissenswert, denn wenn Sie verstehen, wie man sie benutzt, können Sie Googlebot herumkommandieren. Das macht Spaß.
Fangen wir also mit den Grundlagen an: Es gibt drei Möglichkeiten, um zu kontrollieren, welche Teile Ihrer Website von Suchmaschinen gecrawlt werden:
- Noindex: weist Suchmaschinen an, Ihre Seite(n) nicht in die Suchergebnisse aufzunehmen.
- Disallow: weist sie an, Ihre Seite(n) nicht zu crawlen.
- Nofollow: Weist sie an, den Links auf Ihrer Seite nicht zu folgen.
Was ist ein Noindex-Meta-Tag?
Ein „Noindex“-Tag weist Suchmaschinen an, die Seite nicht in die Suchergebnisse aufzunehmen.
Die gängigste Methode, eine Seite zu noindexieren, ist das Hinzufügen eines Tags im Head-Bereich des HTML oder in den Antwort-Headern. Damit Suchmaschinen diese Informationen sehen können, darf die Seite nicht bereits in einer robots.txt-Datei gesperrt (disallowed) sein. Wenn die Seite über Ihre robots.txt-Datei blockiert ist, wird Google das noindex-Tag nie sehen und die Seite könnte trotzdem in den Suchergebnissen erscheinen.
Um Suchmaschinen mitzuteilen, dass Ihre Seite nicht indiziert werden soll, fügen Sie einfach das Folgende in den </head> Abschnitt ein:
<meta name=“robots“ content=“noindex, follow“>
Der zweite Teil des Content-Tags gibt hier an, dass allen Links auf dieser Seite gefolgt werden soll, was wir weiter unten besprechen werden.
Alternativ kann das noindex-Tag auch in einem X-Robots-Tag im HTTP-Header verwendet werden:
X-Robots-Tag: noindex
Weitere Informationen finden Sie im Beitrag von Google Developers zu den Spezifikationen des Robots-Meta-Tags und des X-Robots-Tags im HTTP-Header.
Wie kann ich Noindex in einer Robots.txt-Datei?
Ein „noindex“-Tag in Ihrer robots.txt-Datei weist Suchmaschinen ebenfalls an, die Seite nicht in die Suchergebnisse aufzunehmen, aber es ist ein schnellerer und einfacherer Weg, viele Seiten auf einmal zu noindexieren, besonders wenn Sie Zugriff auf Ihre robots.txt-Datei haben. Zum Beispiel könnten Sie alle URLs in einem bestimmten Ordner noindexieren.
Hier ist ein Beispiel für eine noindex-Direktive, die in der robots.txt-Datei platziert werden könnte:
Noindex: /robots-txt-noindexed-page/
Jedoch rät Google von dieser Methode ab: John Mueller hat erklärt, dass man sich nicht darauf verlassen sollte.
Was ist eine Disallow-Direktive?
Eine Seite zu disallowieren bedeutet, dass Sie Suchmaschinen mitteilen, sie nicht zu crawlen, was in der robots.txt-Datei Ihrer Website geschehen muss. Dies muss in der robots.txt-Datei Ihrer Website geschehen. Es ist nützlich, wenn Sie viele Seiten oder Dateien haben, die für die Leser oder den Suchverkehr nicht von Nutzen sind, da es bedeutet, dass Suchmaschinen keine Zeit damit verschwenden, diese Seiten zu crawlen.

Um ein Disallow hinzuzufügen, fügen Sie einfach Folgendes in Ihre robots.txt-Datei ein:
Disallow: /your-page-url/
Wenn die Seite externe Links oder kanonische Tags hat, die auf sie zeigen, könnte sie immer noch indiziert und gerankt werden, daher ist es wichtig, ein Disallow mit einem noindex-Tag zu kombinieren, wie unten beschrieben.
Ein Wort der Vorsicht: Wenn Sie eine Seite verbieten, entfernen Sie sie effektiv von Ihrer Website.
Gesperrte Seiten können keinen PageRank an andere Seiten weitergeben – daher sind alle Links auf diesen Seiten aus SEO-Sicht nutzlos – und das Sperren von Seiten, die eigentlich enthalten sein sollten, kann katastrophale Folgen für Ihren Traffic haben, also seien Sie besonders vorsichtig, wenn Sie Disallow-Direktiven schreiben.
Wie kann ich Noindex und Disallow kombinieren?
Noindex (Seite) + Disallow: Disallow kann nicht mit noindex auf der Seite kombiniert werden, da die Seite blockiert wird und Suchmaschinen sie daher nicht crawlen können, um zu wissen, dass sie die Seite nicht aus dem Index lassen sollen.
Noindex (robots.txt) + Disallow: Dies verhindert, dass Seiten im Index erscheinen, und verhindert auch, dass die Seiten gecrawlt werden. Denken Sie aber daran, dass kein PageRank durch diese Seite gehen kann.
Um ein Disallow mit einem Noindex in Ihrer robots.txt zu kombinieren, fügen Sie einfach beide Direktiven in Ihre robots.txt-Datei ein:
Disallow: /beispiel-seite-1/
Disallow: /beispiel-seite-2/
Noindex: /beispiel-seite-1/
Noindex: /example-page-2/
Was ist ein Nofollow-Tag?
Ein Nofollow-Tag auf einem Link weist Suchmaschinen an, den Link nicht zu verwenden, um über die Wichtigkeit der verlinkten Seiten (PageRank) zu entscheiden oder weitere URLs innerhalb derselben Site zu entdecken.
Gebräuchliche Verwendungszwecke für nofollow sind Links in Kommentaren und anderen Inhalten, die Sie nicht kontrollieren, bezahlte Links, Einbettungen wie Widgets oder Infografiken, Links in Gastbeiträgen oder alles, was nicht zum Thema gehört, auf das Sie aber trotzdem verlinken wollen.
Historisch haben SEOs auch selektiv Links nofollowt, um den internen PageRank auf wichtigere Seiten zu lenken.
Nofollow-Tags können an einer von zwei Stellen hinzugefügt werden:
- Das <head> der Seite (um alle Links auf dieser Seite nofollowt): <meta name=“robots“ content=“nofollow“ />
- Der Linkcode (um einen einzelnen Link zu nofollowen): <a href=“beispiel.html“ rel=“nofollow“>Beispielseite</a>
Ein Nofollow verhindert nicht, dass die verlinkte Seite komplett gecrawlt wird; es verhindert nur, dass sie über diesen speziellen Link gecrawlt wird. Unsere eigenen Tests und andere haben gezeigt, dass Google eine URL, die es in einem nofollow-Link findet, nicht crawlen wird.
Google gibt an, dass, wenn eine andere Website auf dieselbe Seite verlinkt, ohne ein nofollow-Tag zu verwenden, oder die Seite in einer Sitemap erscheint, die Seite trotzdem in den Suchergebnissen erscheinen kann. Ähnlich verhält es sich, wenn es sich um eine URL handelt, die den Suchmaschinen bereits bekannt ist, wird sie durch das Hinzufügen eines nofollow-Links nicht aus dem Index entfernt.
Im September 2019 kündigte Google ein Update der nofollow-Richtlinie an und führte zwei neue Link-Attribute ein, diese sind:
- rel=“sponsored“ – Das sponsored-Attribut sollte verwendet werden, um Links zu kennzeichnen, die zu Werbezwecken dienen, bei denen Sponsoring- und Vergütungsvereinbarungen bestehen.
- rel=“ugc“ – Als Attribut für User Generated Content wird dieser Wert für Links innerhalb von User Generated-Content-Seiten empfohlen, zum Beispiel für Forenbeiträge und Blog-Kommentare.
Außerdem werden nun alle mit nofollow, sponsored oder ugc gekennzeichneten Links als Hinweis darauf behandelt, welche Links in der Suche und beim Crawling berücksichtigt werden sollen, und nicht mehr nur als Signal, wie es zuvor für nofollow verwendet wurde. Mehr zu diesem Update erfahren Sie in unserem Beitrag, in dem wir auch die Auswirkungen und Expertenmeinungen zu diesem Thema vorstellen.
Was ist Noindex Nofollow?
Wie bereits erwähnt, kann das Hinzufügen eines nofollow-Tags zu einer Seite nicht verhindern, dass diese komplett gecrawlt wird. Um zu verhindern, dass sie indiziert wird, müssen Sie die Seite also auch noindexieren. Dadurch kann Google die Seite immer noch crawlen, aber sie wird nicht im Index erscheinen. Zu den Seiten, die Sie wahrscheinlich nicht indizieren möchten, gehören: Admin-/Login-Seiten, interne Suchergebnisse und Registrierungsseiten. Um zu verhindern, dass Google die Seite komplett crawlt, sollten Sie sie ebenfalls verbieten (siehe oben).
Weitere Direktiven: Canonical Tags, Paginierung und Hreflang
Es gibt weitere Möglichkeiten, Google und anderen Suchmaschinen mitzuteilen, wie URLs behandelt werden sollen:
- Canonical Tags teilen Suchmaschinen mit, welche Seite aus einer Gruppe ähnlicher Seiten indiziert werden soll. Kanonisierte (d. h. sekundäre) Seiten, die Suchmaschinen auf eine primäre Version verweisen, werden nicht in den Index aufgenommen. Wenn Sie getrennte mobile und Desktop-Seiten haben, sollten Sie die mobilen URLs auf die Desktop-URLs kanonisieren.
- Paginierung gruppiert mehrere Seiten zusammen, damit Suchmaschinen wissen, dass sie Teil eines Sets sind. Suchmaschinen sollten beim Ranking der Seiten die erste Seite jedes Satzes bevorzugen, aber alle Seiten innerhalb des Satzes bleiben im Index.
- Hreflang teilt Suchmaschinen mit, welche internationalen Versionen desselben Inhalts für welche Region bestimmt sind, so dass sie die richtige Version für jede Zielgruppe bevorzugen können. Alle diese Versionen bleiben im Index.
Wie viel Zeit sollten Sie in die Reduzierung des Crawl-Budgets investieren?
In SEO-Foren wird oft darüber gesprochen, wie wichtig die Crawl-Effizienz und das Crawl-Budget für SEO sind, und obwohl es gängige Praxis ist, große Gruppen von Seiten, die keinen Nutzen für Suchmaschinen oder Leser haben (z. B. Backend-Code, der nur für den Betrieb der Website verwendet wird, oder einige Arten von Duplicate Content), zu deaktivieren und nicht zu indexieren, ist die Entscheidung, viele einzelne Seiten auszublenden, wahrscheinlich nicht der beste Einsatz von Zeit und Mühe.
Google indiziert gerne so viele URLs wie möglich, daher ist es normalerweise in Ordnung, die Entscheidung Google zu überlassen, es sei denn, es gibt einen speziellen Grund, eine Seite vor Suchmaschinen zu verstecken. In jedem Fall wird Google, auch wenn Sie Seiten vor Suchmaschinen verbergen, weiterhin überprüfen, ob sich diese URLs geändert haben. Das ist besonders dann relevant, wenn es Links gibt, die auf diese Seite zeigen; selbst wenn Google die URL vergessen hat, könnte es sie wieder entdecken, wenn das nächste Mal ein Link zu ihr gefunden wird.
Testen mit Search Console, DeepCrawl und Robotto
Testen Sie die robots.txt mit Search Console
Das robots.txt-Tester-Tool in der Search Console (unter Crawl) ist eine beliebte und weitgehend effektive Methode, um eine neue Version Ihrer Datei auf Fehler zu prüfen, bevor sie live geht, oder eine bestimmte URL zu testen, um zu sehen, ob sie gesperrt ist:
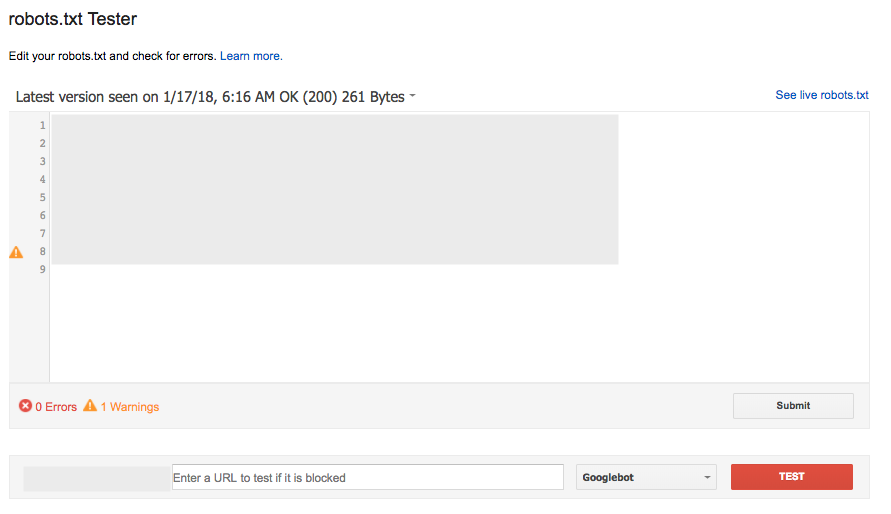
Dieses Tool funktioniert jedoch nicht genau so wie das von Google, mit einigen subtilen Unterschieden in den widersprüchlichen Allow/Disallow-Regeln, die die gleiche Länge haben.
Das robots.txt-Testtool meldet diese als Erlaubt, allerdings hat Google gesagt: „Wenn das Ergebnis undefiniert ist, können robots.txt-Auswerter entscheiden, ob sie das Crawling erlauben oder verbieten. Aus diesem Grund ist es nicht empfehlenswert, sich auf eines der beiden Ergebnisse zu verlassen.‘
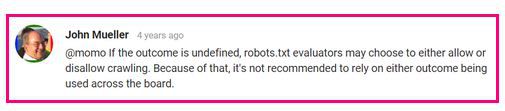
Für weitere Details lesen Sie diese Diskussion im Webmaster Central Help Forum.
Finden Sie alle nicht-indizierbaren Seiten mit DeepCrawl
Lassen Sie einen Universal-Crawl ohne jegliche Einschränkungen (aber mit den robots.txt-Bedingungen), damit DeepCrawl alle Ihre URLs zurückliefert und Ihnen alle indizierbaren/nicht-indizierbaren Seiten anzeigt.
Wenn Sie URL-Parameter haben, die mit der Search Console für den Googlebot blockiert wurden, können Sie dieses Setup für Ihren Crawl nachahmen, indem Sie das Feld Remove Parameters unter Advanced Settings > URL Rewriting verwenden.
Sie können dann die folgenden Berichte verwenden, um zu überprüfen, ob die Website beim ersten Crawl so eingerichtet ist, wie Sie es erwarten würden, und sie dann bei nachfolgenden Crawls mit den eingebauten Änderungsprotokollen kombinieren.
Indexierung > Noindex-Seiten
Dieser Bericht zeigt Ihnen alle Seiten, die ein Noindex-Tag in den Meta-Informationen, dem HTTP-Header oder der robots.txt-Datei enthalten.
Indexierung > Disallowed Pages
Dieser Bericht enthält alle URLs, die aufgrund einer Disallow-Regel in der robots.txt-Datei nicht gecrawlt werden können. Die Zahlen für diese beiden Berichte finden Sie im Dashboard Ihres Berichts:
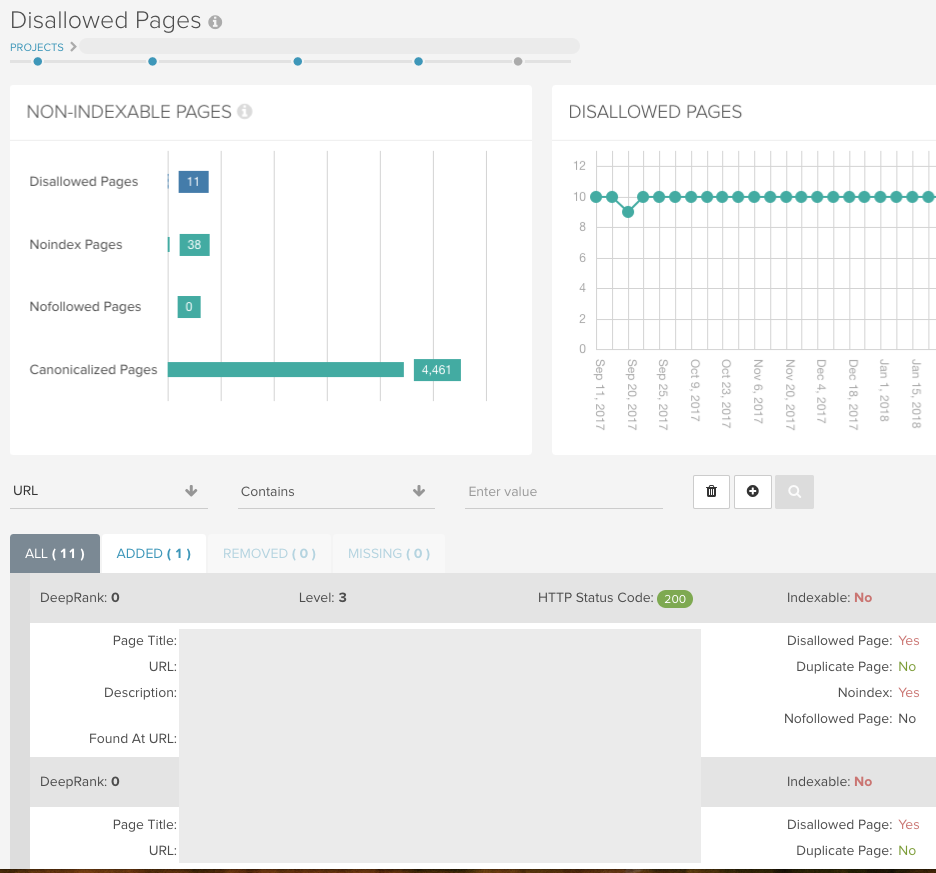
Nutzen Sie unser intuitives Reporting in jedem unserer Berichte, um bestimmte Ordner zu überprüfen und Muster in URLs zu erkennen, die Sie sonst vielleicht übersehen würden:

Testen Sie eine neue robots.txt-Datei mit DeepCrawl
Verwenden Sie die DeepCrawl-Funktion Robots.txt-Überschreibungsfunktion von DeepCrawl in den erweiterten Einstellungen, um die Live-Datei durch eine benutzerdefinierte zu ersetzen.

Sie können dann Ihre Testversion anstelle der Live-Version verwenden, wenn Sie das nächste Mal einen Crawl starten.
Die Berichte „Added“ und „Removed Disallowed URLs“ zeigen dann genau an, welche URLs von den geänderten robots.txt betroffen sind, was die Auswertung sehr einfach macht.
Weitere Informationen finden Sie in unserer Anleitung zur Verwaltung von robots.txt-Änderungen mit DeepCrawl.
Wollen Sie mehr davon?
Wir hoffen, dass Sie diesen Beitrag nützlich fanden, um mehr über noindex, nofollow und disallow zu erfahren, um das Crawling Ihrer Website zu kontrollieren.
Sie können mehr über diese Themen in unserer Technical SEO Library lesen oder wenn Sie lernen möchten, wie Sie ein technisches SEO-Audit durchführen, lesen Sie unseren Leitfaden.
Wenn Sie außerdem daran interessiert sind, über die neuesten Updates und Best-Practice-Empfehlungen von Google auf dem Laufenden zu bleiben, sollten Sie sich in unsere E-Mails einschreiben.
Loop Me In!
Autor

Sam Marsden
Sam Marsden ist der SEO & Content Manager von DeepCrawl. Sam spricht regelmäßig auf Marketing-Konferenzen wie der SMX und BrightonSEO und schreibt für Branchenpublikationen wie das Search Engine Journal und State of Digital.